FLOPs는 다양한 딥러닝 모델들의 논문을 볼 때 연산량을 나타내는 지표로써 많이 사용된다.
FLOPs를 포함한 연산량과 관련된 지표를 간단히 정리하면 다음과 같다.
- FLOPs는 FLoating point Operations의 약자로, 부동소수점 연산을 의미한다. FLOPs의 연산은 산칙연산을 포함해 Root, log, exp 등의 연산도 포함되며, 각각을 1회의 연산으로 계산한다.
- FLOPS는 Floating point Operations Per Second로, 초당 부동소수점 연산을 의미함으로, 하드웨어의 퍼포먼스 측면을 확인하는 지표이다.
- MAC은 현대 하드웨어들이 tensor의 연산을 할 때 사용되는 명령어 셋인 FMA가 a*x+b를 하나의 연산으로 처리하여 이 연산이 몇 번 실행되었는지 세는 것이다. 따라서 1MAC = 2FLOPs이다.
딥러닝 모델 내에서 주로 사용되는 연산들의 FLOPs는 다음과 같다.
Dot product
Dot product는 벡터의 내적으로, 길이가 n인 두 벡터를 내적할 때 곱셈이 n번, 덧셈이 n-1번 실행되어 총 FLOPs는 2n-1이다.
Fully connected layer
FC layer는 말 그대로 input과 output이 완전히 연결되어 있다. input이 n개, output이 m개라면 input에 대한 내적이 output 개수 만큼 계산되기 때문에 총 FLOPs는 (2n-1)xm이다.
Convolution 연산
1. Standard convolution
batch size를 제외한 conv 연산의 input은 CxHxW의 3차원 tensor일 때 kerner_size가 KxK라면 총 FLOPs는 아래와 같다.

위 수식에서 여기서 K*K*Cin까지는 KxK 사이즈의 kernel이 한 번 사용될 때 input의 channel개수 만큼 연산됨을 의미한다. 뒤의 C_out, H_out, W_out이 전부 output의 차원으로 계산되는 이유는, stride와 padding의 결과물로 output의 개수가 정해지고, 결국 앞의 K*K*Cin의 연산의 횟수가 output feature map의 크기만큼 이루어지기 때문이다.
위 수식에서 kernel이 적용될 때의 덧셈이 제외되었는데, 전체 연산에 비해 이 횟수는 매우 적기 때문에 보통 생략한다고 한다.
2. Depth-wise Seperable Convolution
Standard convolution의 연산이 상당히 많기 때문에, 많은 연구들에서 이런 연산을 줄이고자 노력했고, 대표적인 방법이 Depthwise seperable convolution이다.

위 그림은 Depth-wise Convolution을 나타낸 것으로, KxK 사이즈의 kernel이 output feature map의 크기만큼 연산되어 FLOPs가 같아 아래와 같다.

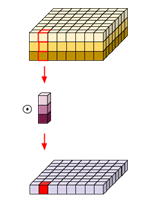
Seperable convolution은 Point-wise convolution으로, Point-wise convolution은 1x1 convolution이다. 따라서 총 FLOP는 아래와 같다.

따라서 총 Depth-wise Seperable Convolution의 FLOPs는 다음과 같다.

따라서 Standard convolution과 비교해 총 FLOPs가 1/Cin배 줄어드는 효과가 있다.
Activation function
- ReLU는 x->y를 일대일 대응시키기 때문에 길이가 n인 input이라면 FLOPs는 n이다.
- Sigmoid는 한 번의 연산인 y = 1/(1+exp(-x))에서 연산이 4번 일어나기 때문에 길이가 n인 input이라면 FLOPs는 4n이다.
'DL > modules' 카테고리의 다른 글
| BPE(Byte Pair Encoding), WordPiece Tokenization (2) | 2024.01.25 |
|---|---|
| Loss function (1) | 2024.01.22 |
| Normalization의 종류 (0) | 2024.01.16 |


