EDA(Exploratory Data Analysis, 탐색적 데이터 분석)이란, 모델링에 앞서 데이터를 살피는 모든 과정을 의미한다. EDA는 데이터 분석의 가장 첫 번째 단계로, 다음과 같은 일을 진행한다.
- 데이터의 특징과 데이터에 내재된 관계를 알아내기 위해 그래프와 통계적 분석 방법을 활용해 데이터를 탐구한다.
- 분석하고자 하는 자료들의 유형과 범위, 수준을 확인하고 단독/여러 변수를 사용해 그 분포와 의미를 고찰한다.
- 분석 목적을 달성하기 위한 알고리즘을 결정하기 전 데이터를 전처리하는 방법과 적합한 알고리즘을 결정하기 위한 자료로 사용된다.
또한, 다음과 같은 네 가지 주제로 구분된다.
- 저항성의 강조 : 이상치 등 부분적 변동에 대한 민감성 확인
- 잔차 계산 : 관찰 값들이 주 경향에서 벗어난 정도 파악
- 자료변수의 재표현 : 변수를 적당한 척도로 바꾸는 것
- 그래프를 통한 현시성 : 분석 결과를 이해하기 쉽게 시각화하는 것
본 글에서는 시각화 위주로 다룬다
1. 막대그래프
막대그래프는 범주형 데이터를 요약하는데 효과적인 그래프이다. 일반적으로 다음과 같은 사항에 사용된다.
- 범주별 빈도수를 시각화
- 범주별 다른 변수의 통계량(평균, 최대, 최소 등)을 시각화
insight?
- 범주별 (타겟변수)빈도수가 차이가 극단적일 경우, 전처리 과정에서 업/다운 샘플링 등을 통해 각 범주의 개수가 유사하도록 조정
- 범주별 (타겟변수)빈도수가 차이가 많이 나지 않을 경우, 분류에서 데이터 분할 시 stratified sampling
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_wine
wine_load = load_wine()
wine = pd.DataFrame(wine_load.data, columns = wine_load.feature_names)
wine['Class'] = wine_load.target
wine['Class'] = wine['Class'].map({0:'Class0', 1:'Class1', 2:'Class2'})
wine_type = wine['Class'].value_counts()
plt.figure(figsize = (20, 20))
plt.subplot(2, 1, 1)
plt.bar(wine_type.index, wine_type.values)
plt.subplot(2, 1, 2)
plt.barh(wine_type.index, wine_type.values)
2. 히스토그램
히스토그램은 연속형 자료에 대한 도수분포표를 시각화하여 나타낸 것으로 서로 겹치지 않는 특정 구간에 따른 데이터의 빈도수를 표현한다.
=> 구간별 빈도수 분포
insight?
- 정규분포인지? -> 정규성 검정으로 이어짐
plt.figure(figsize = (20, 12))
plt.title('Wine alchol', fontsize = 50)
plt.hist('alcohol', bins = 8, range=(11, 15), color = 'orange', data=wine)
plt.show()
3. Box Plot
Box plot은 사분위수를 이용해 수치형 변수 값의 분포를 확인하는 그래프이다. 상자의 크기, 중앙값, 분포와 대칭 정도, 이상치까지 확인할 수 있다.

insights?
- 데이터의 퍼진 정도를 시각적으로 확인(중앙값 위치 지점에 따라)
- IQR 확인
- 수염과 이를 벗어나는 이상치 확인
from sklearn.datasets import load_iris
iris_load = load_iris()
iris = pd.DataFrame(iris_load.data, columns = iris_load.feature_names)
iris['Class'] = load_iris().target
iris['Class'] = iris['Class'].map({0:'Setosa', 1:'Versicolour', 2:'Virginica'})
plt.figure(figsize = (20, 12))
plt.boxplot(iris.drop(columns = ['Class']))
plt.show()
iris[['sepal width (cm)', 'Class']].boxplot(by='Class')
plt.show()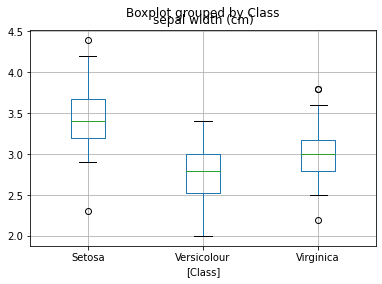
import seaborn as sns
sns.boxplot(x='Class', y='sepal width (cm)', data=iris)
plt.show()
4. Scatter plot
Scatter plot은 두 변수의 관계의 유형과 강도를 판단한다.
insights?
- 점들이 흩어진 형태를 보고 양의 선형관계, 음의 선형관계, 관계없음 등에 대해서 파악한다(두 변수의 관계)
- 적합선에 얼마나 가깝게 모여있는지를 통해 두 변수 간 관계의 강도 추정
- 이후 상관관계 분석을 통해 선형관계의 강도 수치화
plt.title('iris scatter')
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.scatter(x=iris['sepal length (cm)'], y = iris['sepal width (cm)'],
alpha = 0.5)
plt.show()
sns.scatterplot(x = 'sepal length (cm)', y = 'sepal width (cm)',
data=iris, hue='Class', style='Class')
plt.show()
5. 산점도 행렬
산점도 행렬은 두 개 이상의 변수가 있는 데이터들의 변수들 간의 산점도를 그린 그래프이다. 대각선에는 히스토그램 함께 그려 데이터의 분포와 변수들 간의 관계를 알아볼 수 있다.
Insights?
- 대각선의 히스토그램을 통해 이상치를 확인한다.
- 종속변수와 설명변수들 간의 관계를 시각적으로 판단한다.
- 종속변수가 수치형인 경우 각 설명변수와의 직선 상관관계를 비교한다.
- 종속변수가 범주형인 경우 종속변수를 잘 구분하는 변수를 파악한다.
- 설명변수 간의 직선 함수관계를 파악하여 다중공선성 문제를 진단한다.
from pandas.plotting import scatter_matrix
scatter_matrix(iris, alpha = 0.5, figsize = (8, 8), diagonal = 'hist')
plt.show()

sns.pairplot(iris, diag_kind = 'auto', hue = 'Class')
plt.show()
6. 상관계수 행렬 그래프
기본 값은 피어슨 상관계수이며, method 인자로 kendall, spearman으로 변경 가능하다.
iris_corr = iris.corr()
sns.heatmap(iris_corr, annot = True)
plt.show()
etc
보통 처음 데이터셋을 받으면, 나는 datafram.describe()를 통해 각 변수들의 통계량을 대강 확인하고, info()를 통해 수치형과 범주형 변수의 개수, 각 변수들의 결측값의 개수를 파악해둔다.
'ADP로ML정리' 카테고리의 다른 글
| 2-5. 데이터 전처리 - 차원축소 (0) | 2024.02.14 |
|---|---|
| 2-4. 데이터 전처리 - 데이터 분할 및 스케일링 (1) | 2024.02.14 |
| 2-3. 데이터 전처리 - 범주형 변수 처리 (0) | 2024.02.14 |
| 2-2. 데이터 전처리 - 이상치 처리 (0) | 2024.02.14 |
| 2-1. 데이터 전처리 - 결측값 처리 (1) | 2024.02.13 |



