Abstract
기계번역에서 이전의 통계기반 모델과 달리 neural machine 번역은 번역 성능을 최대화 시킬 수 있는 single neural network를 만드는데 초점을 둔다. 이 최근 neural machine들은 encoder-decoder 구조로 source sentence(input)를 고정 길이 벡터로 변환한다.
이 논문에서 고정길이 벡터가 기본적인 encoder-decoder 구조의 아키테쳐의 성능향상을 방해한다고 가정했다. 그리고 target과 관련있는 source sentence의 부분을 자동적으로 찾아내게하는 모델을 제시한다.
Introduction
기존의 encoder-decoder방식의 문제점은 고정길이 벡터에 source sentence의 모든 정보를 담아야하는 것이고, 이는 학습할 때 쓰인 문장보다 긴 source sentence들이 들어올 때 모델링을 어렵게한다. Cho et al. (2014b)에서 기존 encoder-decoder 구조의 모델이 input sentence가 길어질 수록 빠르게 성능이 악화되는 것을 밝혔다.
제시하는 모델은 관련있는 정보가 집중되어 있는 source sentence 내의 위치를 찾아낸다. 모델은 이 source postition과 연계된 context vectors와 이전의 target words들로 target을 예측한다.
제시하는 모델과 기존 모델들의 중요한 차이점은 input을 고정길이 벡터로 변환시키지 않고 벡터들의 시퀀스로 변환 후 decoding 과정에서 벡터의 정보 일부를 고르게 하는 것이다.
이 논문에서, 제시하는 모델은 기존의 모델들보다 상당한 성능향상이 있었으며 특히 긴 문장들에서 그랬다. 또한 모델은 영어-프랑스어 번역 task에서 정성적으로 분석했을 때 target과 source가 언어적으로 그럴듯한 alignment를 찾았다.
Background
parallel training corpus를 통해 sentence pairs의 조건부 확률을 최대화시키기위해 parameterized 모델로 만들었다(fit).
최근 연구들의 neural model들은 variable-length(길이가 다 다른, source와 target) source sentence를 고정길이 벡터로 encode하고 다시 variable-length target으로 변환하는 모델을 제시해왔다. 이것들이 상당히 새로운 접근임에도 이미 neural network machine 번역은 약속된 결과들을 보여줘왔다. (여기서 LSTM을 사용한 번역 task 성능이 좋았음을 언급)
LEARNING TO ALIGN AND TRANSLATE
여기서 새로 제시하는 모델은 인코더와 디코더를 bi-RNN으로 구성한다.
(여기서부턴 밑바닥부터 시작하는 딥러닝2의 내용과 수식을 연결시켜 제가 이해한대로 설명했습니다)
DECODER: GENERAL DESCRIPTION
alignment model
본 논문에서 말하는 alignment model은 맥락벡터 c를 구하기 위한 가중치를 구하는 모델이다.

여기서 hs는 인코더의 output, h는 decoder의 hidden state인데, 논문의 수식과 변수명이 다른데 확인해보자

우선 s(i-1)은 그림상 h, h(j)는 그림상의 hs다. a(ij)는 두 변수로부터 만든 h(j)에 대한 가중치이다

따라서 alignment model을 통해 구한 가중치합으로 맥락벡터 c를 구한다. 여기서 기존의 모델과 다른 주목할 점은 target y(i)에 대해 각기 다른 맥락벡터를 맥락벡터를 통해 확률이 정해진다는 것이다.이렇게 구한 c를 통해 target에 대한 확률을 다음과 같은 수식으로 계산한다.


논문에서는 이 과정을 다음과 같이 그림으로 표현했다

이것을 맥락벡터 c를 구하는 과정을 attention계층으로 도식화해 그리면 다음과 같다
ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
인코더에서는 Bi-RNN을 사용하였습니다. forward RNN으로 input sequence의 원래 순서대로 hidden state값을 출력하고 backward RNN으로 역순서의 hidden state값을 출력합니다.
이를 통해 h(j)는 input 단어의 앞뒤 맥락에 대한 정보를 포함할 수 있습니다.
EXPERIMENT SETTINGS
모델을 평가하기 위해 English-to-French 번역 과제로서 bilingual,parallel corpora provided by ACL WMT ’14.3를 사용했고 비교대상으로 Cho et al. (2014a)의 RNN encoder-decoder를 사용했습니다.
RNN serach -> 본 논문에서 제시한 모델
RNN encoder -> 비교하기위한 기존의 모델
위 두 모델을 단어가 30개로 이루어진 문장들과 50개로 이루어진 문장들을 학습시켰습니다.
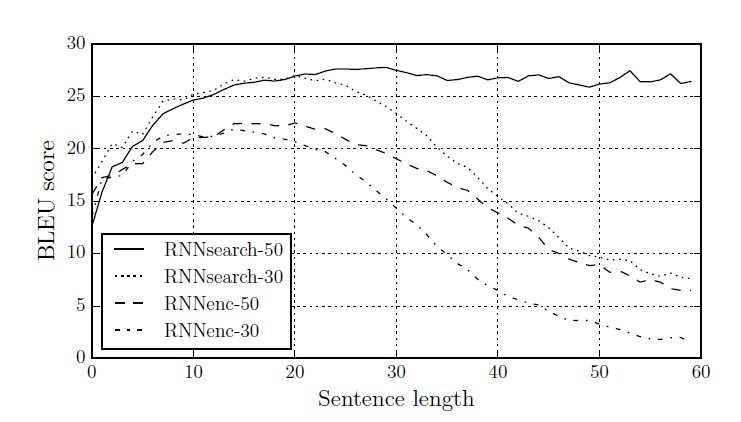
RNN search의 경우 문장의 길이가 길어져도 성능이 떨어지지 않는 모습을 보여줌
Qualitative Analysis
1. alignment
영어 the man의 경우 hard-alignment였다면 the ->l' man -> homme식으로 hard하게 매칭시켰겠지만 soft-alignment의 경우 맥락에 따라 man 앞의 the를 번역할 수 있었다.
2. Long sentences
기존의 RNN encoder-decoder와 비교하여 긴 문장에 대해 더 좋은 성능을 보여준다.
'DL > etc' 카테고리의 다른 글
| diffusion model quick search (0) | 2023.03.24 |
|---|---|
| [논문리뷰] TSM: Temporal Shift Module for Efficient Video Understanding (0) | 2023.01.22 |
| [논문리뷰] EfficientFormer: Vision Transformers at MobileNet Speed (1) | 2023.01.03 |
| [논문리뷰] GolfDB: A Video Database for Golf Swing Sequencing (0) | 2022.12.28 |
| [논문리뷰] Zero-Shot Text-to-Image Generation [DALL-e] (2) | 2022.07.30 |



