GAN(Genrative Adversrial Networks)
GAN은 데이터를 만들어내는 Generator와 만들어진 데이터를 평가하는 Discriminator가 서로 대립적으로 학습해가며 성능을 개선해나가는 모델입니다.

Generator와 Discriminator는 각각 지폐 위조범과 경찰에 비유되어 설명할 수 있습니다. 지폐위조범과 경찰은 서로의 목적을 위해 능력이 발전하고 결과적으로 만들어진 지폐는 진짜와 구별할 수 없을 정도에 이른다는 것입니다.

1. Generator
Generator(이하 G)의 목적은 데이터를 생성해내는 것입니다. G는 input Noise로 가짜 데이터를 만들고 이 데이터를 D의 input으로 넣습니다. 그리고 Back Propagation과정에서 D를 속이는 방향으로 G의 Weight를 업데이트시킵니다. 이 과정에서 D는 에러를 전파만할 뿐 Weight를 업데이트 하지는 않습니다. 이 과정을 Weight Freezing이라고 합니다.
2. Descriminator
D는 진짜 데이터와 가짜데이터를 구별하는 것을 목적으로 합니다. 따라서 G로부터 생성된 가짜데이터와 진짜 데이터를 따로 input으로 받아 학습을 진행합니다.
GAN의 단점
G의 목적이 D를 속이는 것이기 때문에 무조건 D를 속이는 방향으로 특정 데이터를 만들게 되면 올바른 학습에 문제가 생깁니다. 이것을 Mode Collapse라고 합니다.
GAN의 발전 방향
1) GAN 자체의 성능을 높이는 방향
2) Application 부분 - GAN의 학습 특징을 이용해 Domain Adaptation, Style Transfer 등
다양한 GAN 모델
1) BigGAN : 고품질의 이미지를 생성해낼 수 있는 GAN모델
2) CycleGAN : input과 output 간의 domain을 바꿔주는 모델
3) Deep Photo Style Transfer : CycleGAN을 바탕으로 고해상도의 사진에 대해 Transfer시키는 모델
4) Style Transfer for Anime Sketches : Style Transfer의 특징을 이용해 그림에 자동으로 채색해주는 모델
5) StarGAN : input 이미지에 참조 이미지의 피부 표정 등을 Transfer시키는 GAN모형
6) CAN : 예술품을 생성해내는 GAN모형
7) SRGAN : 저해성도의 이미지를 고해상도로 복원하는 GAN 모형
8) Globally and Locally Consistent Image Completion : 사진 속을 랜덤하게 지웠을 때 이를 채워주는 GAN모델
강화학습(Reinforcement Learning)
알파고로 대표적인 강화학습은 현재 상태에서 어떤 행동을 취해야 미래에 보상을 최대로 받을지 학습합니다. 따라서 수많은 시뮬레이션이 필요합니다. 강화학습을 위해서는 많은 episode가 필요하다 보니 주로 GAME환경에서 개발되고 있습니다. 알파고도 바둑이라는 GAME으로 많은 시뮬레이션을 가져옵니다.
Domain Adaptation
Domain Adaptation은 특정 도메인의 데이터가 부족할 때 유사한 도메인 정보를 이용해 문제를 해결하는 방법을 의미합니다.
Continual Learning
지속적으로 학습하는 방법론을 의미합니다. Benchmark Dataset A에 대해 클래스를 분류할 수 있는 모델을 학습해 보유하고 있다고 가정합니다. 이 때 이 데이터셋이 포함되지 않은 새로운 클래스를 분류할 수 있는 모델이 필요하여 새로운 클래스에 대한 데이터와 레이블을 학습된 모델에 추가해 학습을 진행하면, 기존의 Benchmark Dataset A의 분류 능력이 사라집니다. 이를 Catastrophic Forgetting이라합니다.
이 Catastrophic Forgetting를 방지하고 최소화하고자 하는 학습 방식이 Continual Learning입니다. 예를 들어 1년 동안 학습해 얻은 모델에 새로운 클래스의 데이터와 레이블을 추가하여 다시 1년 동안 새로 학습하는 것은 비효율적입니다. 기존의 학습된 모델에 클래스를 추가하되, 기존의 학습된 능력을 잊지 않도록 합니다.
Object Detection
말 그대로 이미지, 비디오 내 특정 객체를 탐지하는 연구 분야를 의미합니다. 분류 문제를 수행함과 동시에 특정 객체가 이미지나 비디오 내 어느 위치에 있는지 위치 정보까지 예측합니다. 특정 좌표(x, y)로부터 가로 세로(width, height)를 함께 예측합니다. 예측 정보로 부터 얻은 특정 객체의 위치를 표시한 네모를 Boundary Box라고 합니다.

object detection은 물체의 위치 정보를 추출하는 Regional Proposal단계와 물체를 분류하는 Classification단계로 나뉩니다. 그리고 이 두 단계를 동시에 처리하는 1 Stage방식과 각 단계에 다른 알고리즘을 적용하는 2Stage 방식이 있습니다. 1 Stage 방식은 주로 YOLO계열의 알고리즘이, 2 Stage 방식은 주로 RCNN계열의 알고리즘이 연구되고 있습니다.
1 Stage 방식은 end-to-end 방식이라 상대적으로 처리 속도가 빠르지만 2 Stage방식에 비해 정확도가 높습니다. 실제 산업에서는 물체를 탐지하는 속도가 중요하기 때문에 1 Stage방식이 많이 연구되고있습니다.
Segmentation
Object Detection보다 정교한 탐지를 요구하는 연구분야입니다.
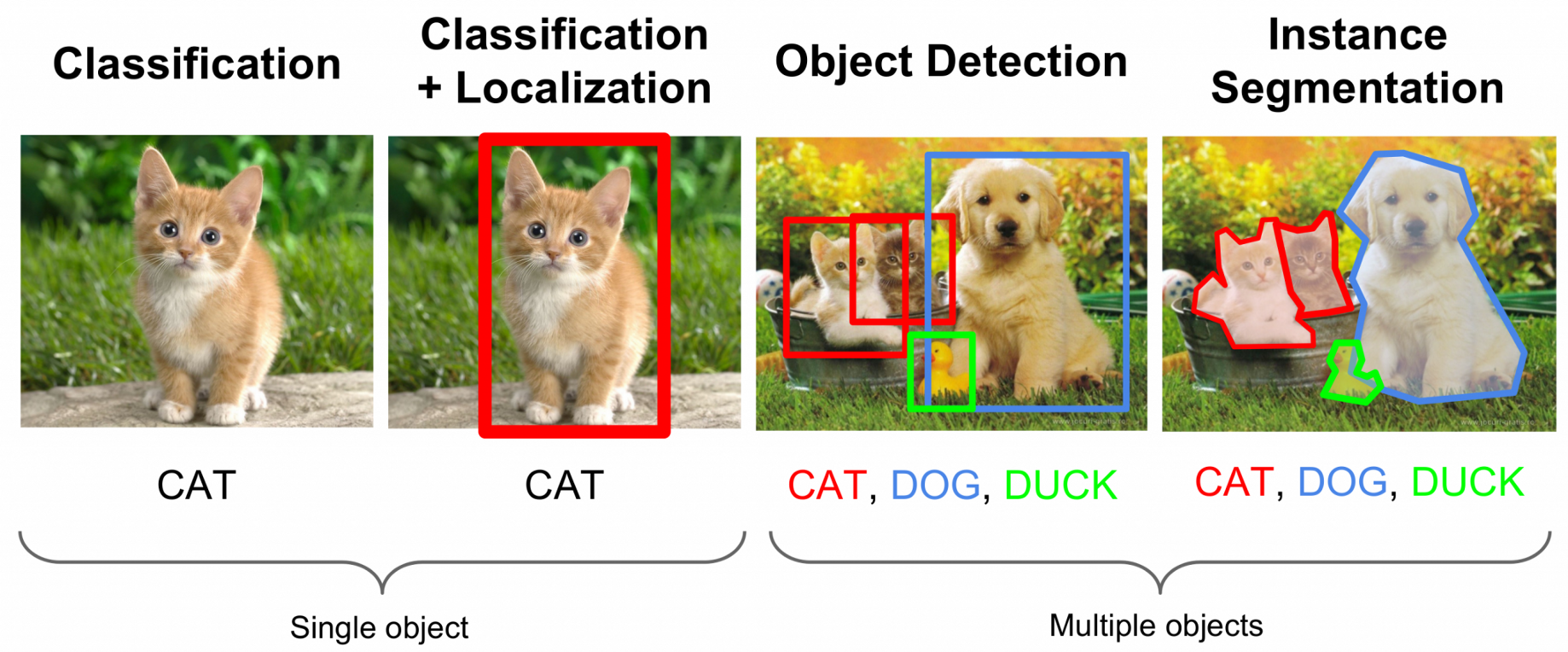
object detection의 경우 Boundary Box안에 객체가 아닌 픽셀이 포함되지만 Segmentation의 경우 위 그림을 보면 알 수 있듯이 객체를 픽셀단위로 추출할 수 있습니다.
Meta Learning
"학습하는 방법을 학습하는 것"을 의미합니다. 대표적인 방법론은 경사하강법을 사용해 오차역전파법을 진행할 때, 최소한의 업데이트로 최소의 Loss 값을 가질 수 있도록 하는 것을 목표로 하며 "학습이 빠르게 되는 초기 파라미터 분포를 찾는 것"이 이에 대한 방법론입니다.
AutoML
컴퓨터가 스스로 모델을 설계하는 것입니다. 다양한 영역 중 대표적으로 Data Augmentation기법을 자동으로 설계해 학습 효율을 최대로 끌어올리는 Auto Augmentation, 특정 Task를 풀기 위해 딥러닝 모델 구조를 자동으로 설계하는 Neural Architecture Search를 예로 들 수 있습니다.