머신러닝의 프로세스는 데이터 가공/변환 -> 모델 학습/예측 -> 평가(Evaluation)로 구성됩니다.
분류모델에서의 특정 성능 평가 지표를 특정 모델에 중요하다고 할 순 있으나, 한 지표만을 보고 평가했다가는 잘못된 결과에 빠질 수 있습니다. 따라서 여러가지 지표들의 특성을 이해해야합니다.
분류는 결정 클래스 값 종류의 유형에 따라 이진분류와 여러 개의 결정 클래스 값을 가지는 멀티 분류 나뉠 수 있습니다. 본 글에서 볼 성능 지표는 모두 적용되는 지표이지만, 이진 분류에서 더욱 중요하게 강조되는 지표입니다.
지표에 대해 하나하나 정리한 후, 지표를 불러오는 코드를 마지막 순서로 작성하겠습니다!
1. 오차행렬(confusion matrix)
오차행렬이란?
- 학습된 분류 모델이 예측을 수행하면서 얼마나 헷갈리고(confused) 있는지 보여주는 지표입니다.
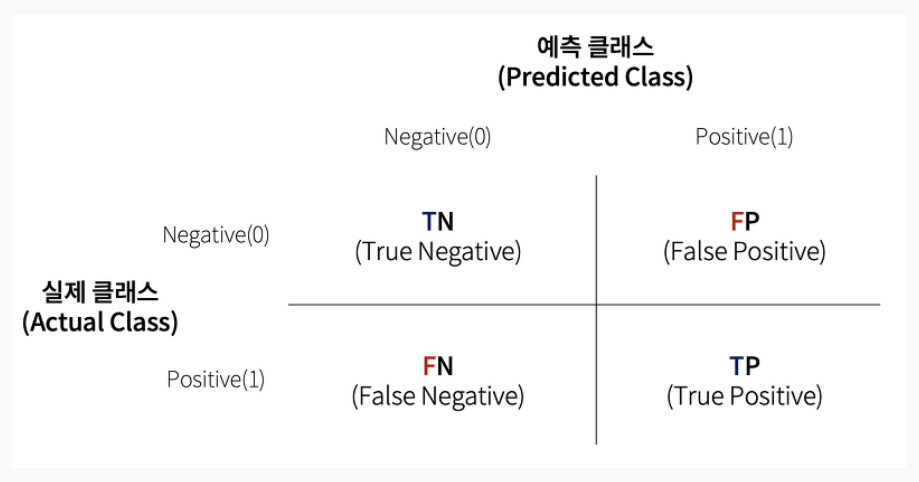
여기서 True는 예측값과 실제값이 같다는 의미이며, False는 그 반대입니다
사분면 내 True or False의 뒤에 오는 Negative와 Positive는 예측값입니다.
ex) TN의 경우, Negative로 예측한 값이 실제값도 Negative인 경우입니다.
2. 정확도(accuracy)
정확도란? 정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표입니다.

정확도는 모델 예측 성능을 직관적으로 나타내는 지표이지만, 데이터의 구성에 따라 모델의 성능을
왜곡할 수 있기 때문에 정확도 수치만을 가지고 성능을 평가하지 않습니다.
예를 들어 타이타닉 생존 여부 데이터셋을 보면, 남자인 경우보다 여자인 경우에 생존 확률이 높았기
때문에 별다른 알고리즘의 적용 없이 여자인 경우 생존, 남자인 경우 사망으로 예측해도 높은 정확도가
나올 수 있습니다. 단지 하나의 성별(feature)를 가지고 결정하는 알고리즘이 높은 정확도가 나오는 상황이
발생합니다.
3. 정밀도(precision)과 재현율(recall)

정밀도란 Positive로 예측한 값 중 실제값도 Positive인 비율이고, 재현율은 실제 Positive값이 Positive로 예측된 비율입니다.
여기서 짚고 갈 부분은 처음 Negative와 Positive가 처음에 헷갈릴 수 있습니다. 단순 직역으로
긍정, 부정의 의미가 아니라 예측을 통해 찾아내려는 경우가 Positive, 그 외의 값이 Negative라고 이해했습니다.
예를 들어, 암 진단검사를 할 때 찾아내려는 값인 양성이 Positive, 음성이 Negative입니다.
또한 금융사기 적발 모델에서 찾아내려는 값인 사기 금융거래 건이 Positive, 정상 금융거래 건이
Negative라고 볼 수 있습니다.
위의 암 진단검사와 금융사기 적발 모델에서 Negative(암 음성, 정상 금융거래)를 Positive(암 양성, 사기 금융거래)로
예측한 경우(FP) 재검사 또는 재확인하는 절차를 거치면 되지만, 그 반대인 경우(FN) 손해가 클 것입니다. 따라서 위와
같은 경우들은 재현율이 중요한 경우입니다.
정밀도가 중요한 경우는 위 문단의 예시와 반대로 FP일 때 손해가 큰 경우입니다. 예를 들어 스팸 메일 분류 모델에서
실제 스팸 메일(Positive)를 일반메일(Negative)로 분류해도(FN) 큰 불편함이 없지만, 그 반대인 경우(FP) 일반 업무메일이 스팸 메일로 분류될 경우, 손해가 클 것입니다.
4. 각 지표들 불러오기
- 본 코드는 타이타닉 생존여부 데이터셋의 분류 이후 평가입니다.

내 생각
오차행렬의 각 값으로부터 정확도와 같은 지표들이 계산되는데 책에서는 정확도가 먼저 나오고 오차행렬을 소개하는 것을 보고 처음에는 살짝 의아했지만, 정확도만을 지표로 삼았을 때 나타나는 문제를 먼저 설명하여 순서가 합리적이라고 다시 생각하게되었다.
#본 글은 위키북스의 "파이썬 머신러닝 완벽 가이드"를 베이스로 저의 학습을 정리한 글로,
제가 어떻게 이해했느냐에 따라 책의 내용과 달라질 수 있습니다.
'AI_basic > ML' 카테고리의 다른 글
| [ML] GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 같이 (0) | 2021.07.21 |
|---|---|
| [ML] 지도학습/분류 결정트리 Decision Tree (0) | 2021.07.13 |
| [ML] 분류모델의 성능 평가 지표 Part3. F1_score, ROC_curve and AUC (0) | 2021.07.07 |
| [ML] 분류모델의 성능 평가 지표 Part.2 정밀도/재현율 트레이드오프(Trade-off) (0) | 2021.07.07 |
| [ML] 사이킷런(Scikit-learn)으로 머신러닝 맛보기(붓꽃 품종 예측) (0) | 2021.07.06 |



