코드구현 : https://github.com/hits-gold/MDGAN-pytorch
1. Contributions
- 결함이미지 생성에서 paired trainig input이 부족한 문제를 해결하는 pseudo-normal backgounds를 구성하고, CyclaGAN의 의존성을 피했다.
- MDGAN을 제안하고, 이것은 normal backgrounds, defect shape, defcet texture를 독립적으로 컨트롤한다. BRM(Background replacement module)는 normal background를 보존하고 binary annotation을 받아들인다. DDM(double discrimination module) 결함 영역과 전체 이미지에 동시에 집중하여 생성 이미지의 퀄리티를 높인다.
- BRM이 normal background를 보존함에 따라 MDGAN은 다른 데이터셋끼리 결함을 섞을 수 있다.
2. Methods
2.1. Pseudo-Normal Background
- N = 앙품이미지 D = 결함 이미지 M = 마스크
이 때 T(아핀 변환 행렬)를 사용해 N^c를 얻는다. 이 때 T_x, T_y는 아핀 변환 파라미터이다. 아핀 변환은 빈 영역을 채우는데 사용되는 양품이미지에서의 영역을 결함 영역과 정렬될 수 있게 한다.
- M_ = 1-M
N^c를 최종적으로 D의 결함 영역을 채우는데 사용한다.
B = (결함 이미지의 배경영역) + (아핀변환된 양품이미지의 결함 이미지에서의 결함영역)

이 때 T(아핀 변환 행렬)를 사용해 N^c를 얻는다. 이 때 T_x, T_y는 아핀 변환 파라미터이다. 아핀 변환은 빈 영역을 채우는데 사용되는 양품이미지에서의 영역을 결함 영역과 정렬될 수 있게 한다.
- M_ = 1-M
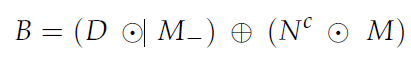
N^c를 최종적으로 D의 결함 영역을 채우는데 사용한다.
B = (결함 이미지의 배경영역) + (아핀변환된 양품이미지의 결함 이미지에서의 결함영역)
2.2 MDGAN
2.2.1. Architectures
- 위 그림과 같이 MDGAN의 Generator는 U-net과 같은 형태를 띈다. input으로는 가우시안 노이즈, pseudo-normal background, binary mask가 적용된다. Discriminator는 결함 이미지와 binary

2.2.1. Architectures
- 위 그림과 같이 MDGAN의 Generator는 U-net과 같은 형태를 띈다. input으로는 가우시안 노이즈, pseudo-normal background, binary mask가 적용된다. Discriminator는 결함 이미지와 binary mask를 input으로 처리하는 patchGAN을 도입했다.
- BRM은 binary mask를 사용해 실제 배경을 feature map의 특정 위치에 합성시킨다.
- DDM(double discrimination module)은 discriminator의 feature map을 background와 결함 영역으로 나눈다. 이후 결함 영역에 대한 feature를 추출한 이후 background와 다시 결합시킨다. 이 과정을 DDM없이는 두 개의 discriminator를 사용해야한다.
2.2.2 Trainig Objectives
- N = 앙품이미지 D = 결함 이미지(gt) D^r = generator output M = binary mask
- M_ = 1-M B = pseudo normal background
- 가우시안 분포에서 추출한 random noise z를 M에 매핑하고, B에 더해 generator의 첫 convolution layer input을 만든다.

2. Generator를 통해 결함 이미지를 생성하고, reconstruction loss를 계산한다.
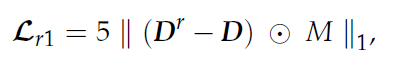
3. 다른 rancom noise z를 적용해 D’을 만들고, diversity loss를 계산한다.
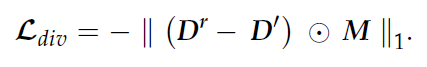
- 본질적으로 D^r과 D’는 결함 영역만 다른 같은 결함 이미지로부터 생성된 것이다.
4. Normal background losses
- Normal background losses

- 마지막 BRM의 의존성을 피하고 결함 영역과 final output의 normal background와의 일치성을 위해 마지막 BRM의 input인 dl을 사용한 loss를 추가한다.

5. replacement 이후 결함 영역과 background의 일치성을 위해 두 영역 사이의 경계에서 gradient loss를 계산한다. (Whole image losses)
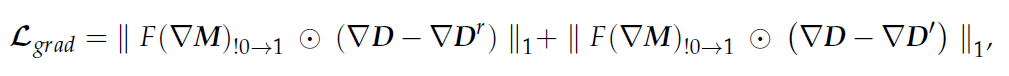
- 여기서 F(x)_!0→1는 non-zero to one을 의미한다.
6. 학습 프로세스를 안정시키기 위해 WGAN-GP의 gradient penalty를 추가한다.
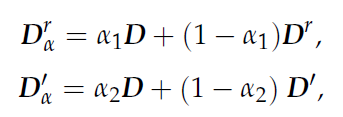
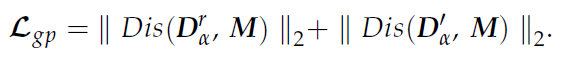
- 여기서 감마 상수는 각 loss들에 적용되는 가중치 파라미터이다
3. Datasets
- dataset으로는 MVTec-AD를 사용한다.
3.1. Training Sets
- Training Sets는 MVTec-AD의 grid, zipper, capsul, metal nut을 사용하고, 일부 결함 요인에 대해 그룹화를 진행했다.
3.2. Test Sets
- MDGAN test를 위한 binary mask를 얻기 위해 다음과 같은 두 가지 방법을 사용했다.
- MVTec-AD에서 제공하는 많은 binary mask를 MDGAN의 input에 맞춰 crop
- 결함을 다양한 모양으로 생성하기 위해 Perlin noise를 binary mask에 적용했다.

4. Experiments
- MDGAN은 3의 데이터셋의 이미지들에 결함을 합성하기 위해 사용된다.
- metal nut과 capsule은 3 channels, 나머지는 grayscale된 이미지들을 포함한다.
4.1. Implementations
- Method에서 언급한 pseudo-normal background를 형성하는 과정에서 OpenCV의 getRotationMatrix2D()와 warpAffine() 사용
- training image는 rotation, flipping, random cropping을 통해 augment
- binary mask는 [-1, 1]로 정규화 후 모델에 input으로 적용, loss 계산 시 [0, 1]로 변환
- 12개의 convolution layers의 output은 64, 128, 256, 256, 512, 512, 512, 256, 256, 128, 64로 구성.
- discriminator의 경우 32, 128, 256, 256, 512, 1로 구성.
- latent space dimension은 8
- 전체 loss에 쓰인 가중치 파라미터는 r=10, d=15, g=10, gp=10
- Adam optimizer는 B1=0.5, B2=0.999이고 batch size=20, lr=0.0004, iterations=500
- GPU = RTX 3090, CPU = Intel(R) Xeon(R) Gold 622306R
- grid 이미지에서는 마지막 BRM 제거 → backgrouds는 마지막 BRM없이 얻어지는 경우가 있어, 이 경우 구조 단순화
4.2. Synthetic Results
- (a)는 다른 normal backgroud 이미지들에 같은 binary mask를 적용해 한 유형의 결함을 합성한 것이다.
- (b)는 같은 normal backgroud 이미지로부터 5개의 다른 binary mask와 3개 유형의 결함을 합성한 것이다.
- (c)는 하나의 normal background 이미지에 같은 binary mask를 사용해 다른 유형의 결함 5개를 합성한 것이다.
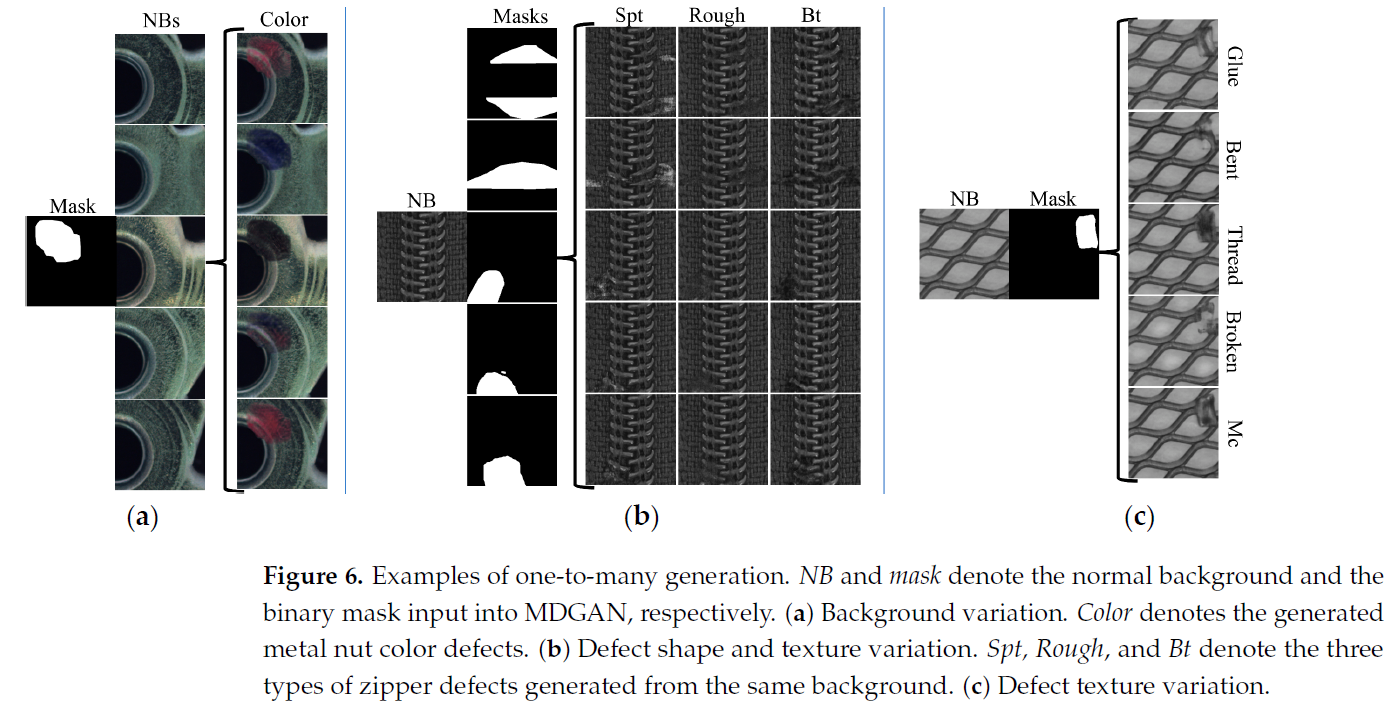
- (a)는 다른 normal backgroud 이미지들에 같은 binary mask를 적용해 한 유형의 결함을 합성한 것이다.
- (b)는 같은 normal backgroud 이미지로부터 5개의 다른 binary mask와 3개 유형의 결함을 합성한 것이다.
- (c)는 하나의 normal background 이미지에 같은 binary mask를 사용해 다른 유형의 결함 5개를 합성한 것이다.
5. etc
- 이 외에 BRM과 DDM에 대한 ablation study, CylcleGAN과의 comparison study가 논문에 작성되어있다.
- Detection Performance는 다음과 같다.
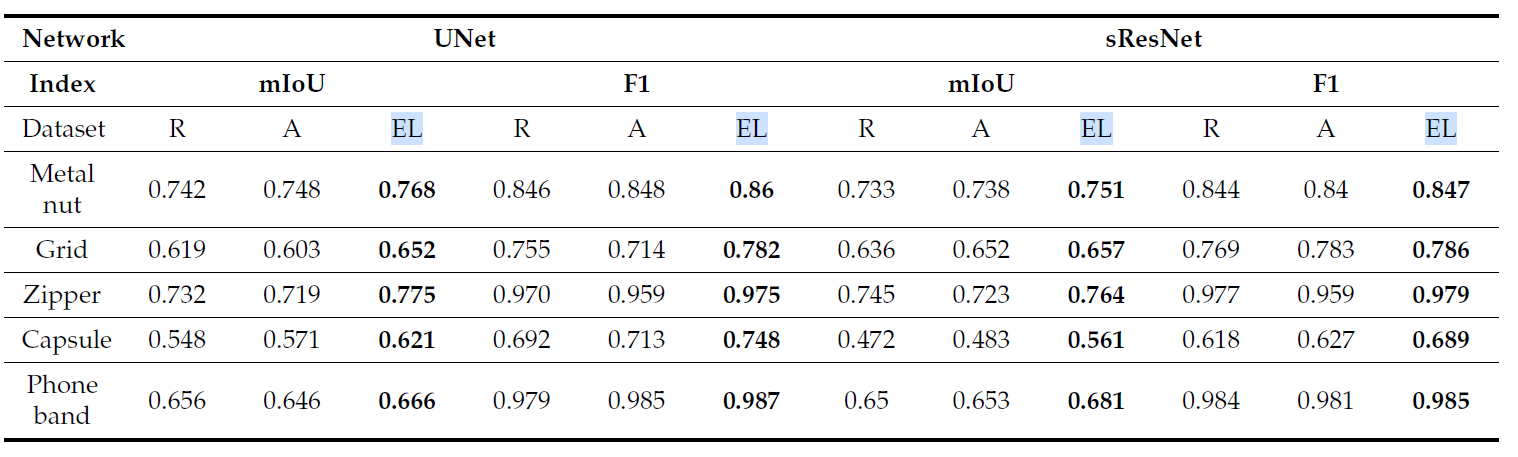
- R = raw images, A = traditional augmentation, EL = MDGAN augmentation
'DL > etc' 카테고리의 다른 글
| diffusion model quick search (0) | 2023.03.24 |
|---|---|
| [논문리뷰] TSM: Temporal Shift Module for Efficient Video Understanding (0) | 2023.01.22 |
| [논문리뷰] EfficientFormer: Vision Transformers at MobileNet Speed (1) | 2023.01.03 |
| [논문리뷰] GolfDB: A Video Database for Golf Swing Sequencing (0) | 2022.12.28 |
| [논문리뷰] Zero-Shot Text-to-Image Generation [DALL-e] (4) | 2022.07.30 |



