반응형
코드 : https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/object_detection/YOLOv3
1. DarkNet + Multi-scale feature map extracter

YOLO v3에서는 DarkNet-53이라는 새로운 Backbone network가 등장한다. 총 53개의 conv layer로 이루어져있다.
"""
Implementation of YOLOv3 architecture
"""
import torch
import torch.nn as nn
"""
Information about architecture config:
Tuple is structured by (filters, kernel_size, stride)
Every conv is a same convolution.
List is structured by "B" indicating a residual block followed by the number of repeats
"S" is for scale prediction block and computing the yolo loss
"U" is for upsampling the feature map and concatenating with a previous layer
"""
config = [
(32, 3, 1),
(64, 3, 2),
["B", 1],
(128, 3, 2),
["B", 2],
(256, 3, 2),
["B", 8],
(512, 3, 2),
["B", 8],
(1024, 3, 2),
["B", 4], # To this point is Darknet-53
(512, 1, 1),
(1024, 3, 1),
"S",
(256, 1, 1),
"U",
(256, 1, 1),
(512, 3, 1),
"S",
(128, 1, 1),
"U",
(128, 1, 1),
(256, 3, 1),
"S",
]
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, bn_act=True, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=not bn_act, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.leaky = nn.LeakyReLU(0.1)
self.use_bn_act = bn_act
def forward(self, x):
if self.use_bn_act:
return self.leaky(self.bn(self.conv(x)))
else:
return self.conv(x)
class ResidualBlock(nn.Module):
def __init__(self, channels, use_residual=True, num_repeats=1):
super().__init__()
self.layers = nn.ModuleList()
for repeat in range(num_repeats):
self.layers += [
nn.Sequential(
CNNBlock(channels, channels // 2, kernel_size=1),
CNNBlock(channels // 2, channels, kernel_size=3, padding=1),
)
]
self.use_residual = use_residual
self.num_repeats = num_repeats
def forward(self, x):
for layer in self.layers:
if self.use_residual:
x = x + layer(x)
else:
x = layer(x)
return x
class ScalePrediction(nn.Module):
def __init__(self, in_channels, num_classes):
super().__init__()
self.pred = nn.Sequential(
CNNBlock(in_channels, 2 * in_channels, kernel_size=3, padding=1),
CNNBlock(
2 * in_channels, (num_classes + 5) * 3, bn_act=False, kernel_size=1
),
)
self.num_classes = num_classes
def forward(self, x):
return (
self.pred(x)
.reshape(x.shape[0], 3, self.num_classes + 5, x.shape[2], x.shape[3])
.permute(0, 1, 3, 4, 2)
)
class YOLOv3(nn.Module):
def __init__(self, in_channels=3, num_classes=80):
super().__init__()
self.num_classes = num_classes
self.in_channels = in_channels
self.layers = self._create_conv_layers()
def forward(self, x):
outputs = [] # for each scale
route_connections = []
for layer in self.layers:
if isinstance(layer, ScalePrediction):
outputs.append(layer(x))
continue
x = layer(x)
if isinstance(layer, ResidualBlock) and layer.num_repeats == 8:
route_connections.append(x)
elif isinstance(layer, nn.Upsample):
x = torch.cat([x, route_connections[-1]], dim=1)
route_connections.pop()
return outputs
def _create_conv_layers(self):
layers = nn.ModuleList()
in_channels = self.in_channels
for module in config:
if isinstance(module, tuple):
out_channels, kernel_size, stride = module
layers.append(
CNNBlock(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=1 if kernel_size == 3 else 0,
)
)
in_channels = out_channels
elif isinstance(module, list):
num_repeats = module[1]
layers.append(ResidualBlock(in_channels, num_repeats=num_repeats,))
elif isinstance(module, str):
if module == "S":
layers += [
ResidualBlock(in_channels, use_residual=False, num_repeats=1),
CNNBlock(in_channels, in_channels // 2, kernel_size=1),
ScalePrediction(in_channels // 2, num_classes=self.num_classes),
]
in_channels = in_channels // 2
elif module == "U":
layers.append(nn.Upsample(scale_factor=2),)
in_channels = in_channels * 3
return layers
if __name__ == "__main__":
num_classes = 20
IMAGE_SIZE = 416
model = YOLOv3(num_classes=num_classes)
x = torch.randn((2, 3, IMAGE_SIZE, IMAGE_SIZE))
out = model(x)
assert model(x)[0].shape == (2, 3, IMAGE_SIZE//32, IMAGE_SIZE//32, num_classes + 5)
assert model(x)[1].shape == (2, 3, IMAGE_SIZE//16, IMAGE_SIZE//16, num_classes + 5)
assert model(x)[2].shape == (2, 3, IMAGE_SIZE//8, IMAGE_SIZE//8, num_classes + 5)
print("Success!")
1. _creat_conv_layer() 함수를 통해 conv layer를 쌓는 과정을 살펴보면 다음과 같다.
- 기본적으로 config에서 tuple이 들어오면 CNNBlock 클래스를 통해 conv layer를 만든다.
- BN과 activation function은 기본적으로 사용하게 되어있는데, 모든 conv layer에 BN+leaky_relu가 적용되게 되어있다.
- BN을 모든 conv layer 뒤에 추가하는 것으 YOLO v2에 나오는 설정이다.
- config 값이 ["B", n]인 경우는 short connection이 포함된 block을 n번 반복한다(ResidualBlock).
- 이 때 ResidualBlock으로 들어올 때는 channel이 반으로, 나갈 때는 두 배가 되어 Block에 입력되기 전과 channel size는 같아진다.
- Block 내 두 개의 conv layer의 kernel size는 각각 1x1, 3x3(s2)로 모두 같다.
2. Multi-scale feature map 추출은 다음과 같다.
- YOLOv3 클래스의 forward 과정에서 위의 두 Level의 feature map은 route connection 리스트에 삽입된다.
- 마지막 feature map(13x13)은 그대로 Scaleprediction 과정에 입력되며, 이 때 forward의 x는 변하지 않는다.
- Scaleprediction의 최종 과정에 들어가기 전의 변형된 마지막 feature map은 "U"를 만나 업샘플링되고, route connection의 마지막 feature map(두 번째 Level)의 feature map과 concat 된후, 이것이 x가 된다.
- 여기서 Scaleprediction을 만나면, Residual Block을 활용해 feature map이 최종 Output으로 갈 때까지의 Block들을 포함시키기 때문에 Upsampling 이전 Block들이 생성된다.(여기서 좀 헤맸다;; _creat_conv_layer()에서 ScalePrediction을 만나면 Upsampling 직전의 conv layer들을 전체 Layer에 포함시켜 config에 나와있지 않은 conv layer가 생성된다.. ResidualBlock인데 short connection을 쓸 건지 정하는 인자가 왜 있는지 여기서 알게 됨.....)
- 위 과정이 가장 높은 Level의 feature map까지 반복된다.
- ScalePrediction을 통해 나온 최종 Multi-scale output은 (B, C, H, W)의 순서대로 있는데, 하나의 grid cell에 255개(3개 anchor box에 대한 값)에 있어 B와 C 차원을 유지하면서 나머지 값을 anchor box와 class prob + (좌표값, objectness_score)으로 변환해주는 것으로 보인다.
최종적으로 아래 그림에서 볼 수 있는 Multi-scale feature map 3개가 outputs로 출력된다.
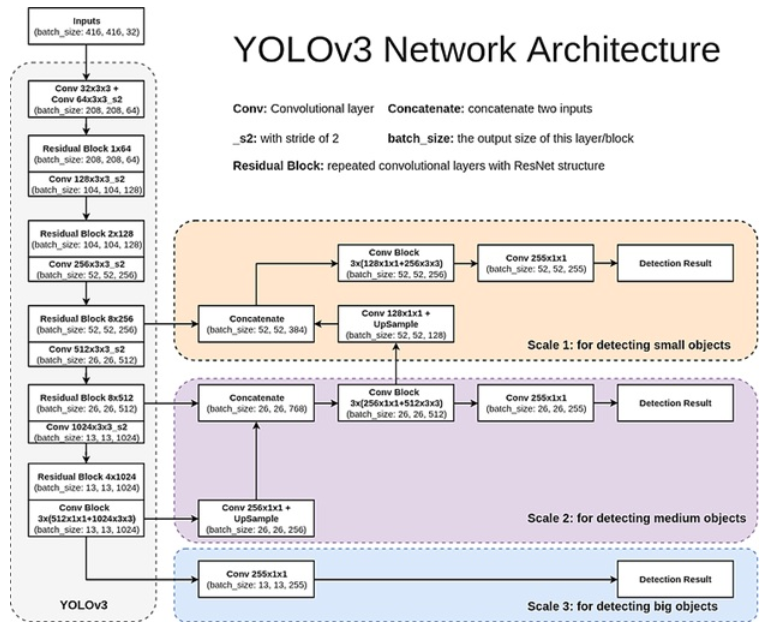
마지막으로 랜덤한 값을 가지는 tensor를 입력해 Multi-scale feature map이 논문 상의 size대로 나오는지 확인하는 것까지 마음에 든다!
2. Loss
Loss는 논문에 구체적으로 언급되어 있지 않은데, 다음 4개 항으로 구성되어 있다.
- bbox offset의 MSE
- objectness score의 BCE
- no_objectness score의 BCE
- bbox의 multi-class BCE
"""
Implementation of Yolo Loss Function similar to the one in Yolov3 paper,
the difference from what I can tell is I use CrossEntropy for the classes
instead of BinaryCrossEntropy.
"""
import random
import torch
import torch.nn as nn
from utils import intersection_over_union
class YoloLoss(nn.Module):
def __init__(self):
super().__init__()
self.mse = nn.MSELoss()
self.bce = nn.BCEWithLogitsLoss()
self.entropy = nn.CrossEntropyLoss()
self.sigmoid = nn.Sigmoid()
# Constants signifying how much to pay for each respective part of the loss
self.lambda_class = 1
self.lambda_noobj = 10
self.lambda_obj = 1
self.lambda_box = 10
def forward(self, predictions, target, anchors):
# Check where obj and noobj (we ignore if target == -1)
obj = target[..., 0] == 1 # in paper this is Iobj_i
noobj = target[..., 0] == 0 # in paper this is Inoobj_i
# ======================= #
# FOR NO OBJECT LOSS #
# ======================= #
no_object_loss = self.bce(
(predictions[..., 0:1][noobj]), (target[..., 0:1][noobj]),
)
# ==================== #
# FOR OBJECT LOSS #
# ==================== #
anchors = anchors.reshape(1, 3, 1, 1, 2)
box_preds = torch.cat([self.sigmoid(predictions[..., 1:3]), torch.exp(predictions[..., 3:5]) * anchors], dim=-1)
ious = intersection_over_union(box_preds[obj], target[..., 1:5][obj]).detach()
object_loss = self.mse(self.sigmoid(predictions[..., 0:1][obj]), ious * target[..., 0:1][obj])
# ======================== #
# FOR BOX COORDINATES #
# ======================== #
predictions[..., 1:3] = self.sigmoid(predictions[..., 1:3]) # x,y coordinates
target[..., 3:5] = torch.log(
(1e-16 + target[..., 3:5] / anchors)
) # width, height coordinates
box_loss = self.mse(predictions[..., 1:5][obj], target[..., 1:5][obj])
# ================== #
# FOR CLASS LOSS #
# ================== #
class_loss = self.entropy(
(predictions[..., 5:][obj]), (target[..., 5][obj].long()),
)
#print("__________________________________")
#print(self.lambda_box * box_loss)
#print(self.lambda_obj * object_loss)
#print(self.lambda_noobj * no_object_loss)
#print(self.lambda_class * class_loss)
#print("\n")
return (
self.lambda_box * box_loss
+ self.lambda_obj * object_loss
+ self.lambda_noobj * no_object_loss
+ self.lambda_class * class_loss
)
이해는 다 되었는데,objectness_score에 BCE가 아닌 MSE가 쓰인 것과 Bbox multi-classification에 BCE가 아닌 CCE가 쓰인 것은 논문과 다른 내용인 것 같다.
uitls.py에 NMS도 같이 있는데, 다른 모델들도 많이 쓰는 알고리즘이라 다른 코드로 구해서 리뷰할거임
반응형
'DL > Code' 카테고리의 다른 글
| YOLOv1 Pytorch 코드 리뷰 (1) | 2024.01.25 |
|---|---|
| MDGAN : Mask guided Generation Method for Industrial Defect Images with Non-uniform Structures 코드 구현 및 리뷰 (1) | 2024.01.24 |
| Transformer Pytorch 코드 리뷰 (1) | 2024.01.24 |


