앙상블은 단일 결정 트리의 단점을 극복하기 위해 여러 모델을 연결해 더 강력한 모델을 만드는 방법이다. 즉 주어진 자료로부터 여러 개의 예측 모형을 만든 후 예측모형들을 조합하여 하나의 최종 예측 모형을 만드는 것이다. 편향, 잡음 및 분산으로 인한 오류를 막고 과적합을 방지하기 위해 사용된다.
1. Bagging
Bootstrap
붓스트랩은 랜덤 샘플링의 일종으로 단순임의복원추출법을 적용해 여러 개의 동일한 크기의 표본 자료를 획득하는 방법이다. 주어진 데이터를 모집단을 대표하는 독립 표본으로 가정하고, 그 자료로부터 중복을 허용한 무작위 재추출을 하여 복수의 자료를 획득해 각 집단에서 통계량을 계산한다.

배깅은 이러한 붓스트랩 기법을 활용해 여러 개의 붓스트랩 자료(데이터셋)을 생성해 각각의 붓스트랩 자료에 대한 예측 모델을 만든 후 최종적으로 결합한 모형을 만드는 방식이다. 통계분류와 회귀분석에서 사용하는 머신러닝 알고리즘의 안정성과 정확도를 향상시키기 위해 고안된 일종의 앙상블 학습법의 알고리즘이다.
배깅은 분산을 줄이고 정확도를 개선해 모델의 안정성을 크게 높여 과적합을 방지하는 효과가 있다. 배깅은 다음과 같은 순서로 이루어진다.
- 붓스트래핑
- 단순임의복원추출을 통해 여러 개의 자료 집단을 만든다.
- 모델링
- 각 자료 집단에 대한 예측 모델링을 진행한다.
- 보팅(Voting)
- 여러 개의 모형으로부터 산출된 결과 중 다수결에 의해 최종 결과를 산정한다.(소프트 보팅의 경우 평균)
- 최적 의사결정 트리 구축에서 가장 어려운 가지치기를 진행하지 않고 약한 학습자인 트리를 최대로 성장시킨 후 보팅을 한다.
Out - of - Bag
붓스트랩을 진행하면 평균적으로 전체 집단에서 약 63%의 데이터만 샘플링된다. 이 때 각 예측기에서 선택되지 않은 나머지 37%를 out of bag 샘플이라하고 검증세트로 활용할 수 있다.
- m개의 샘플에서 무작위로 하나를 추출할 때 선택되지 않을 확률 : 1 - (1/m)
- 추출을 n번 반복했을 때도 선택되지 않을 확률 : 1 - (1/m)^n
- n이 무한대로 갈 때 로그를 취하고 로피탈 정리 적용 : e^(-1)
- 샘플링될 확률 : 1 - e^(-1) = 0.63212
2. Boosting
부스팅은 붓스트랩을 병렬로 수행하여 각 모델을 독립적으로 구축하는 배깅과 달리 순차적인 방식으로 학습을 진행한다.

학습에서 데이터 샘플에 가중치를 할당하며 분류결과가 좋지 않은 데이터는 높은 가중치를, 분류결과가 좋은 데이터는 낮은 가중치를 할당 받는다. 높은 가중치를 받은 데이터 샘플은 다음 붓스트래핑에서 추출될 확률이 높아진다. 직전 단계에서 예측력이 약했던 부분을 다음 단계에서 개선해 나가는 방식이다. 따라서 배깅에 비해 모델의 장점을 최적화하고 train 데이터에 대해 오류가 적은 결합모델을 생성할 수 있다는 장점이 있다. 다만 train 데이터에 과적합될 위험이 있다.
3. Random Forest
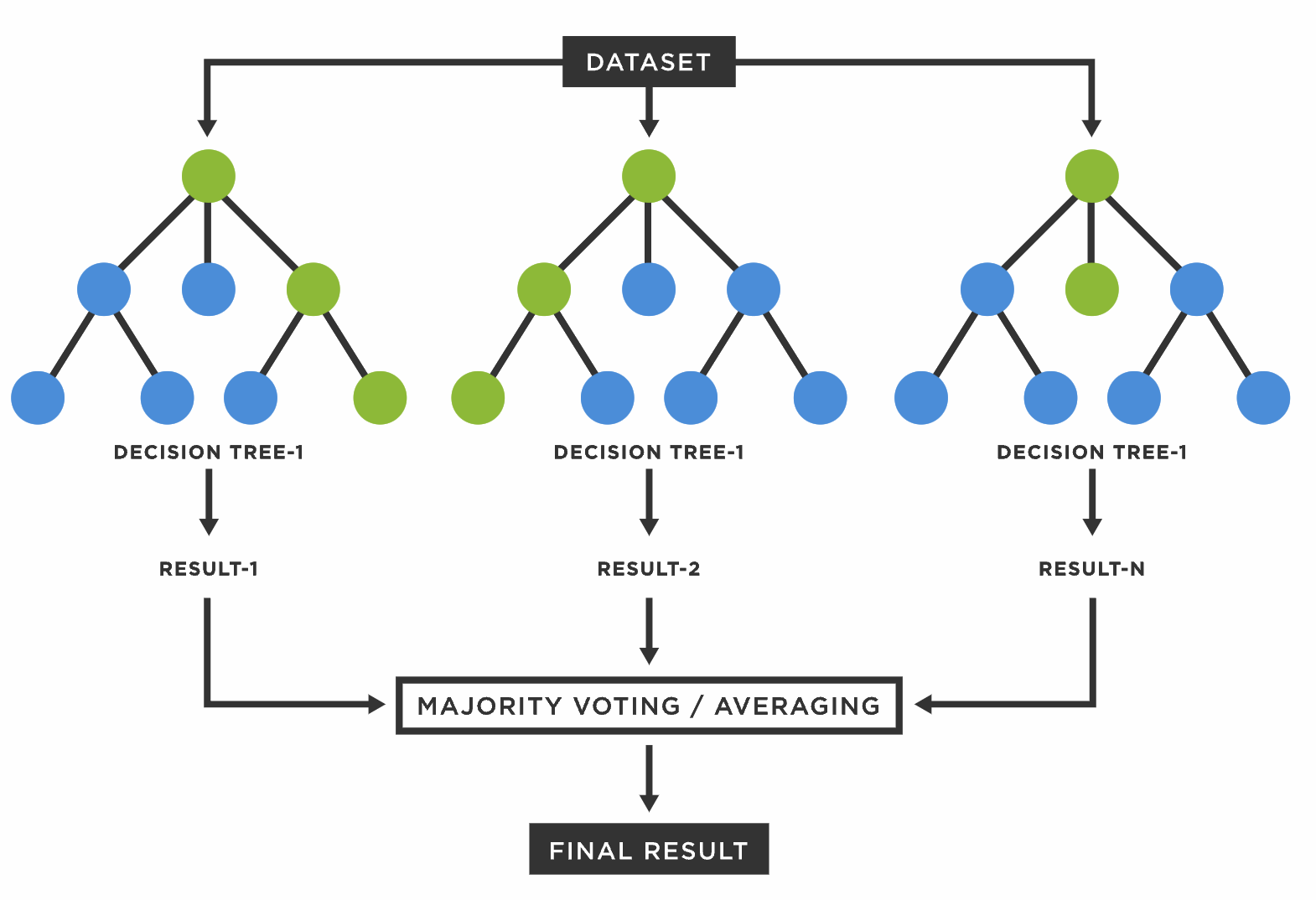
랜덤 포레스트는 배깅의 대표적인 알고리즘으로, 기존 배깅과 부스팅보다 더 많은 무작위성을 주어 이 학습기들을 선형결합해 최종 학습기를 만드는 기법이다.
- Forest
- 수 많은 Tree를 결합함.
- Random
- 기존 배깅과 같이 붓스트랩을 활용해 각 예측기에 적용되는 학습 데이터를 무작위로 추출함
- 각 학습기에서 사용하는 학습 데이터의 feature 또한 무작위로 추출함
- 역설적으로 모든 feature를 활용하기 위해 feature를 무작위로 추출함
- 모든 학습기가 모든 feature를 통해 Tree를 만든다면? -> 모든 학습기가 주요 feature를 통해서 학습을 진행
- 모든 학습기가 feature를 무작위로 추출한다면? -> 최종 학습기는 모든 feature를 고려할 수 있음
from sklearn.datasets import load_breast_cancer
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
cancer = load_breast_cancer()
x = pd.DataFrame(cancer.data, columns = cancer.feature_names)
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(x, y, stratify=y, train_size = 0.7, random_state = 42)
print(X_train.shape, X_test.shape)
from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score
from sklearn.metrics import precision_score, recall_score, f1_score, plot_roc_curve
clf = RandomForestClassifier(max_depth = 5)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
test_cm = confusion_matrix(y_test, pred)
test_acc = accuracy_score(y_test, pred)
test_pre = precision_score(y_test, pred)
test_re = recall_score(y_test, pred)
test_f1 = f1_score(y_test, pred)
print(test_cm)
print('\n')
print(f'정확도 : {round(test_acc*100, 2)}%')
print(f'정밀도 : {round(test_pre*100, 2)}%')
print(f'재현율 : {round(test_re*100, 2)}%')
print(f'F1 score : {round(test_f1*100, 2)}%')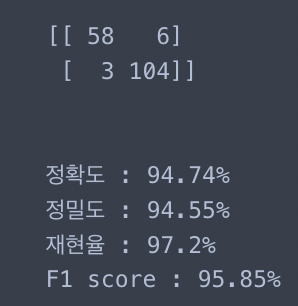
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
report = classification_report(y_test, pred)
print(report)
ra_score = roc_auc_score(y_test, clf.predict_proba(X_test)[:, 1])
print('ROC_AUC_SCORE : ', ra_score)
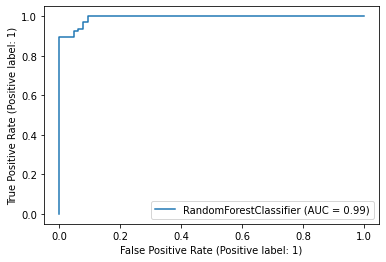
plot_roc_curve(clf, X_test, y_test)
plt.show()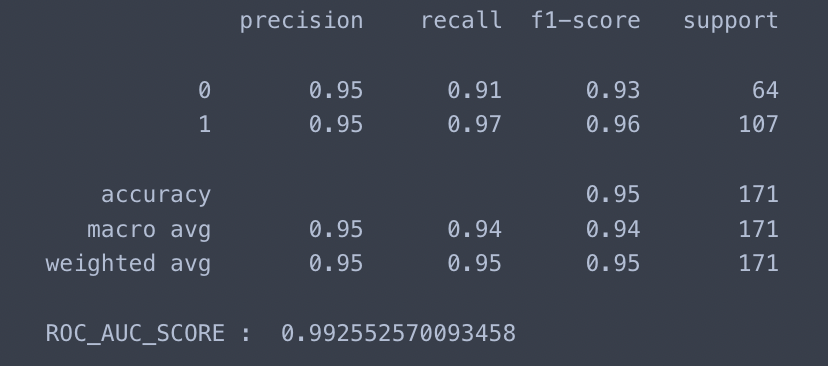
importances = clf.feature_importances_
df = pd.DataFrame(importances, index = x.columns, columns = ['importances'])
df.sort_values(by = 'importances', ascending=False)
'ADP로ML정리' 카테고리의 다른 글
| 5. 의사결정나무 Decision Tree (0) | 2024.02.20 |
|---|---|
| 4-2. 회귀 모델 - 분류를 위한 회귀 모델 (1) | 2024.02.19 |
| 4-1. 회귀 모델 - 규제가 있는 선형 회귀 (1) | 2024.02.19 |
| 3. 머신러닝 평가지표 (0) | 2024.02.15 |
| 2-6. 데이터 전처리 - 데이터 불균형 문제 해결 (1) | 2024.02.15 |



