퍼셉트론에서 신경망으로의 진화
퍼셉트론은 우리가 직접 가중치 매개변수의 적절한 값을 설정해 논리회로들에 맞는 값을 출력할 수 있도록 했습니다. 하지만 신경망은 이 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력이 있습니다.
1. 신경망의 예와 퍼셉트론 복습

그림에도 보이다시피 신경망의 가장 왼쪽 층은 입력층, 중간은 은닉층, 맨 오른쪽은 출력층이라고 합니다. 여기서 여러 신호를 입력받아 하나의 출력신호를 내보내는 퍼셉트론을 확대해 보겠습니다.

여기서 b는 퍼셉트론 수식의 θ를 -b로 치환하여 편향으로 계산해준 것입니다.
- 편향 : 뉴런이 얼마나 쉽게 활성화되느냐를 제어
- 가중치 : 각 신호의 영향력을 제어
2. 활성화 함수

편향을 추가한 퍼셉트론에서 y의 값을 a로 두고, 이 a를 h()라는 함수에 넣어 y라는 함수를 다시 출력값으로 계산했습니다. 이렇게 입력 신호의 총합을 출력 신호로 변환하는 함수를 일반적으로 활성화 함수(activation function)이라고 합니다.
1) 시그모이드 함수


위 그래프에서 실선으로 표시된 곡선이 시그모이드 함수입니다. 계단함수와 달리 매끄러운 곡선을 가지고 있지만 공통적으로 0과 1사이의 값을 출력한다는 것을 알 수 있습니다. 여기서 계단함수는 입력값 0을 경계로 출력이 갑자기 바뀌어버립니다. 하지만 시그모이드 함수는 곡선이여서 입력에 따라 출력이 연속적으로 변화합니다. 이러한 성질때문에 시그모이드 함수는 신경망 학습에서 중요한 역할을 하게됩니다.
여기서 두 함수의 중요한 공통점은 비선형함수라는 것입니다. 신경망의 활성화 함수로는 비선형함수를 사용해야 하는데 왜 그럴까요?
활성화 함수로서 선형함수의 문제는 층을 아무리 깊게 해도 "은닉층이 없는 네트워크"로 똑같은 기능을 할 수 있다는 데 있습니다. 선형함수를 사용해서 층을 깊게 하는 이점을 살릴 수 없다는 증명은 생략하겠습니다.
2) ReLU 함수
시그모이드 함수는 신경망 분야에서 오래전부터 이용해 왔으나 최근에는 ReLU함수를 주로 이용합니다.
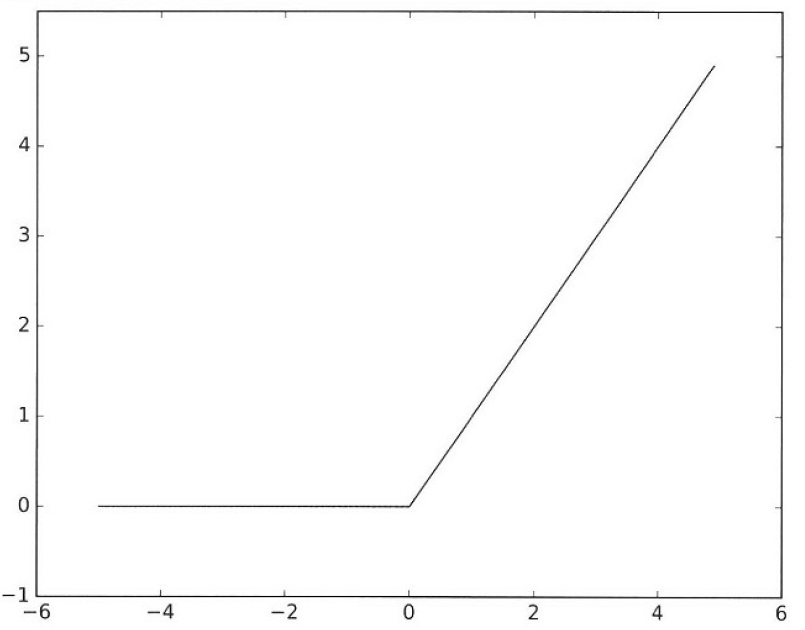
ReLU함수는 입력이 0을 넘으면 그대로, 0이하면 0을 출력합니다.
3. 출력층까지의 3층 신경망 모형 정리
위에서 알아본 편향과 활성화 함수를 사용해 출력층까지의 3층 신경망 모형을 정리해보겠습니다.

편향을 뜻하는 뉴런이 추가되었고, 1층으로 들어온 입력값들의 총합이 활성화 함수를 거쳐나왔습니다.

1층까지의 신호전달과 마찬가지로, 편향을 뜻하는 뉴런이 추가되었고 1층에서 전달된 신호들의 총합이 활성화 함수를 거쳐나왔습니다.
4. 신경망에서의 행렬곱
신경망에서 이전 층의 신호에 가중치를 곱한 총합을 구해 다음 층으로 넘어갈 때, 행렬곱의 원리가 작용한다는 것을 간단히 짚어보겠습니다.
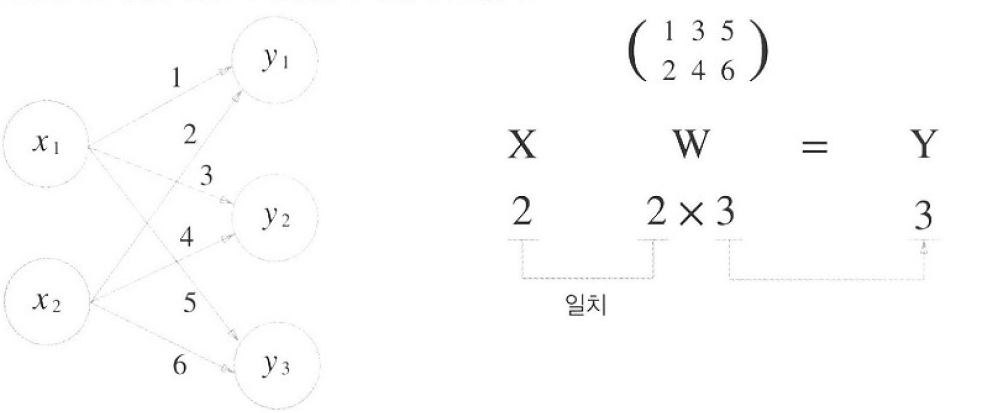
X를 입력값들을 늘어놓은 행벡터로, W를 다음 층의 같은 뉴런에 들어오는 가중치들을 열벡터로 갖는 행렬로 표시하면, X*W = Y와 같은 행렬곱으로 신경망의 계산을 수행할 수 있습니다. 이 행렬곱은 X에 가중치를 곱한 후 그 합을 원소로 갖는 벡터 또는 행렬을 출력하는 형식이기 때문에, 신경망의 계산 수행에 적용될 수 있다는 것을 알 수 있습니다.
5. 출력층 설계
1) 출력층의 활성화 함수 - 소프트맥스 함수
기계학습 문제는 분류와 회귀로 나뉩니다. 신경망에서 출력층의 활성화함수는 일반적으로 회귀에는 항등함수를, 분류에는 소프트맥스함수를 사용합니다.
소프트맥스 함수의 식은 다음과 같습니다.
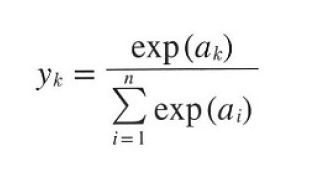
위 식의 n은 출력층의 뉴런 수, yk는 그 중 k번째 출력, ak는 입력신호를 의미합니다. 위 식을 해석하자면, 출력층의 값들을 지수함수에 넣어 변환한 뒤, k번째 값이 전체 출력값 합에서 차지하는 비중을 나타냅니다. 따라서 소프트맥수 함수의 출력의 총합은 1이며, 이는 "확률"로 해석할 수 있습니다.
(지수함수는 단조증가 함수이기 때문에 소프트맥수 함수를 적용시켜도 출력값의 대소관계는 변하지 않습니다. 신경망을 이용한 분류에서는 일반적으로 가장 큰 출력을 내는 뉴런에 해당하는 클래스로만 인식하기 때문에 신경망으로 분류를 할 때는 소프트맥스 함수를 생략해도됩니다. 현업에서도 자원 낭비를 줄이고자 생략하는 것이 일반적입니다.)
2) 소프트맥스 함수 구현시 주의점 - 오버플로
소프트맥스의 함수식은 지수식을 반환하기 때문에 하나의 입력신호가 적당히 클 때 컴퓨터가 지수함수를 무한으로 인식해 출력값을 계산할 수 없습니다. 이 문제를 개선한 수식으로 해결할 수 있습니다.
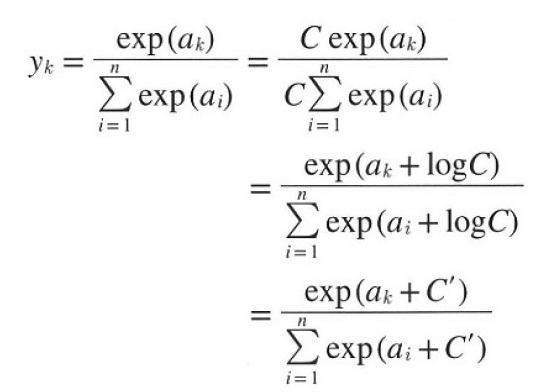
분모와 분자에 같은 상수를 곱했기 때문에 원래의 소프트백수 함수식과 같습니다. 이것을 역으로 계산해보면, 각 입력신호에 어떠한 같은 정수를 더해도 결과가 바뀌지 않는다는 것입니다. 여기서 C는 오버플로를 막을 목적으로는 입력 신호 중 최댓값을 이용하는 것이 일반적입니다.
3) 출력층의 뉴런 수 정하기
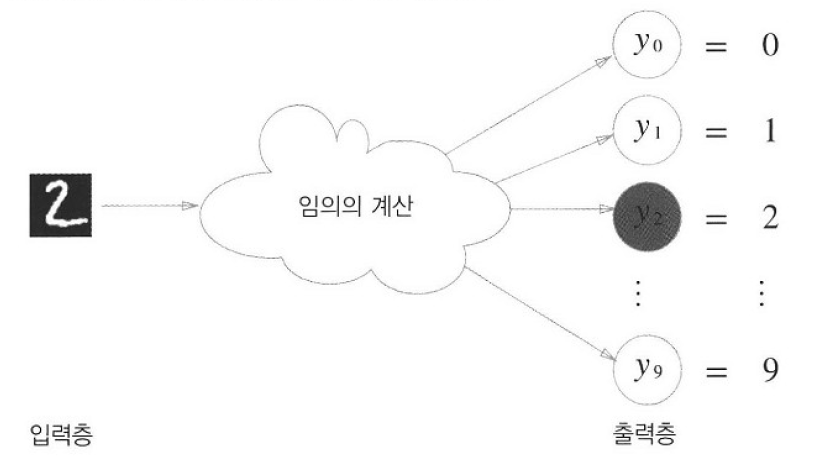
분류에서 출력층의 뉴런 수는 각 클래스값에 대응하기 때문에 분류하는 클래스 개수만큼 지정합니다. 여기서 각 출력값들이 소프트맥스 함수를 거쳐나온 값임을 생각해보면, 각 출력값들은 출력층의 뉴런에 대응하는 클래스의 확률값을 나타냄을 알 수 있습니다.
6. MNIST데이터셋을 이용한 신경망 구현
import sys
import os
import pickle
import numpy as np
import matplotlib.pyplot as plt
# 사이킷런 datasets을 활용해 mnist 데이터셋 불러오기
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784')
# train_test_split
X_train = mnist.data[:60000, :]
t_train = mnist.target[:60000]
X_test = mnist.data[60000:, :]
t_test = mnist.target[60000:]
# 데이터 시각화해보기
plt.imshow(X_train[0].reshape(28, 28), "gray")하나의 손글씨가 784개의 픽셀로 이루어져 있으므로 가로 세로를 784의 제곱근으로 reshape해준 뒤 시각화를 하면 다음과 같은 이미지가 나옵니다.
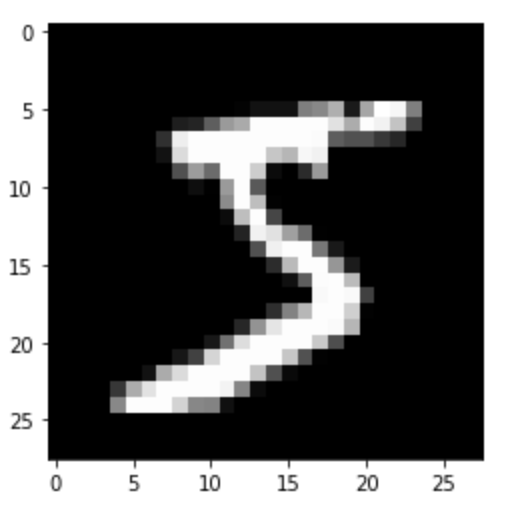
X_train의 shape은 (60000, 784)인데, 이는 한 이미지에 대한 픽셀이 flatten되어 열벡터로, 60000개의 이미지들이 각각 행벡터를 이루는 행렬임을 알 수 있습니다.
이제 각 활성화 함수를 정의하고 신경망을 구현해 보겠습니다.
def sigmoid(x):
return 1/(1 + np.exp(-x))
def softmax(x):
c = np.max(x)
exp_x = np.exp(x-c)
sum_exp_x = np.sum(exp_x)
y = exp_x / sum_exp_x
def init_network():
with open("sample_weight.pkl", 'rb') as f:
# 학습된 가중치 매개변수가 담긴 파일
# 학습 없이 바로 추론을 수행
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = X_test/255, t_test # 정규화
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))위 셀을 실행시키면 "Accuracy:0.9352"가 출력되고, 이는 이 신경망이 올바르게 분류한 비율이 93.52%라는 것을 의미합니다.
(sample_weight.pkl은 가중치 매개변수가 딕셔너리 형태로 저장되어있는 pickle파일입니다. 밑바닥부터 시작하는 딥러닝 github에서 다운받으실 수 있습니다. https://github.com/youbeebee/deeplearning_from_scratch)
'AI_basic > Deeplearning' 카테고리의 다른 글
| [Deeplearning Part .6-1] CNN (1) | 2022.01.09 |
|---|---|
| [Deeplearning Part.5] 학습 관련 기술들 (0) | 2022.01.09 |
| [Deeplearning Part.4] 오차역전파법 (0) | 2022.01.06 |
| [Deeplearning Part.3] 신경망 학습 (0) | 2022.01.06 |
| [Deeplearning Part.1]퍼셉트론과 단순 논리 회로 (0) | 2022.01.05 |



