반응형
1. 파일 분할
각 클래스에 해당하는 이미지 파일들은 다음과 같이 dataset 폴더 내에 각각의 클래스 이름의 폴더 내에 저장되어있습니다.
따라서 각 클래스별로 비율을 같게 학습, 검증, 시험 데이터로 분할해줍니다.
import os
import shutil
origin = "/content/drive/MyDrive/pytorch project/작물 잎 분류/dataset"
base = "/content/drive/MyDrive/pytorch project/작물 잎 분류/splitted"
clss_list = os.listdir(origin)
os.mkdir(base)
train_dir = os.path.join(base, "train")
val_dir = os.path.join(base, "val")
test_dir = os.path.join(base, "test")
os.mkdir(train_dir)
os.mkdir(val_dir)
os.mkdir(test_dir)
for clss in clss_list:
os.mkdir(os.path.join(train_dir, clss))
os.mkdir(os.path.join(val_dir, clss))
os.mkdir(os.path.join(test_dir, clss))-> splitted라는 폴더 생성
-> splitted 폴더 내에 train, val, test폴더 생성
-> 각 train, val, test폴더 내에 클래스 이름으로 되어있는 폴더들 생성
import math
for clss in clss_list:
path = os.path.join(origin, clss)
fnames = os.listdir(path)
train_size = math.floor(len(fnames) * 0.6)
val_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
train_fnames = fnames[:train_size]
for fname in train_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(train_dir, clss), fname)
shutil.copyfile(src, dst)
val_fnames = fnames[train_size : (train_size + val_size)]
for fname in val_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(val_dir, clss), fname)
shutil.copyfile(src, dst)
test_fnames = fnames[(train_size + val_size) : (train_size + val_size + test_size)]
for fname in test_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, clss), fname)
shutil.copyfile(src, dst)-> splitted 폴더의 각 분할된 폴더 내에 이미지 파일 복붙
2. 데이터 준비
import torch
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
use_cuda = torch.cuda.is_available()
print(use_cuda)
device = torch.device("cuda" if use_cuda == 1 else "cpu") # 연산에 사용할 device 정의
path = "/content/drive/MyDrive/pytorch project/작물 잎 분류"
epoch = 10
batch_size = 256
transform_base = transforms.Compose([transforms.Resize((64, 64)), transforms.ToTensor()])
# 이미지 전처리, Augmentation등에 활용, 위 코드는 이미지 크기를 (64, 64)로 조정, 이미지 데이터를 tensor로 변환
train_dataset = ImageFolder(root = path + "/splitted/train", transform = transform_base)
val_dataset = ImageFolder(root = path + "/splitted/val", transform = transform_base)
# 하나의 폴더가 하나의 클래스에 대응하는 구조를 가진 폴더+파일에 사용
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size = batch_size, shuffle = True, num_workers = 4)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size = batch_size, shuffle = True, num_workers = 4)
# 불러온 이미지 데이터를 조건에 맞게 미니배치 단위로 분리하는 역할-> 원본 이미지 파일은 256*256사이즈인데 데이터 준비단계에서 64*64로 조정
-> DataLoader 모듈로 배치 단위로 분할
3. 모델 및 학습, 평가 함수 정의
# 베이스라인 모델 설계
import torch.nn as nn # nn.Module에 딥러닝과 관련된 기본적인 함수들 포함
import torch.nn.functional as F
import torch.optim as optim # 최적화 옵션
class Net(nn.Module): # nn.Module 상속받음 -> 다 끌어와 씀
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding = 1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding = 1)
self.conv3 = nn.Conv2d(64, 64, 3, padding = 1)
# padding=1에 커널 크기3으로 층 지나도 이미지 크기 보존
# Conv2d의 앞 세 개 파라미터 -> 입력 채널 수, 출력 채널 수, 필터사이즈
# 따라서 위 세 개의 합성곱연산을 지나면 채널이 3->32->64->64로, 이미지 크기는 그대로
self.fc1 = nn.Linear(4096, 512) # 합성곱 연산에서 이미지 크기 64*64 --flatten --> 4096을 512로 출력
self.fc2 = nn.Linear(512, 33) # 512받고 33 -> class 개수로 출력
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p = 0.25, training = self.training) # 25%의 노드를 dropout, training -> 학습과정에서만 dropout적용
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p = 0.25, training = self.training)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p = 0.25, training = self.training)
x = x.view(-1, 4096) # numpy의 reshape
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, p = 0.5, training = self.training)
x = self.fc2(x)
return F.log_softmax(x, dim = 1)
model = Net().to(device)
optimizer = optim.Adam(model.parameters(), lr = 0.001) # 최적화 옵션으로 Adam사용-> kerner size=3과 padding=1의 합성곱 연산 ==>> 원본 이미지 해상도 유지
-> fully connected layer 전까지 kerner size=2에 stride=2의 풀링 계층 두 번지나면?
-> 풀링 계층 한 번 지날 때마다 해상도의 두 개 차원 크기는 반감. 따라서 두 번 지나면 이미지 해상도 8*8로 변경
-> 따라서 합성곱 계층을 모두 지나면 8*8*16(채널)크기의 데이터로 변환(계산해보면 4096!)
# 모델 학습을 위한 함수
def train(model, train_loader, optimizer): # 모델 학습에 필요한 것 -> 모델, 데이터, 최적화옵셥
model.train() #모델을 학습모드로 변경
for batch_idx, (data, target) in enumerate(train_loader): # train_loader는 조건에 맞게 미니배치 단위로 나뉘어져있어 여기 for문처럼 변수할당
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # for문이 배치 단위 -> 이전 배치 Gradient값(가중치 미분값) 초기화
output = model(data) # 모델에 input넣고 output뽑기
loss = F.cross_entropy(output, target) # loss값 뽑기
loss.backward() # 오차역전파
optimizer.step() # 역전파한 값들로 모델 파라미터 업데이트
# 모델 평가 함수
def evaluate(model, test_loader):
model.eval() # 모델 평가모드로 변경
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction = "sum").item() # loss값은 교차엔트로피 총합으로! -> default는 mean
pred = output.max(1, keepdim = True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset) # 이전 test_loss는 배치별 loss총합이 더해진 값. 이를 배치 개수로 나누어 평균 계산
test_accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, test_accuracy4. 모델 학습 및 검증데이터 평가 실행
import time
import copy
def train_baseline(model, train_loader, val_loader, optimizer, num_epochs = 30):
best_acc = 0.0
best_model_wts = copy.deepcopy(model.state_dict()) # 정확도 가장 높은 모델 저장
for epoch in range(1, num_epochs+1):
since = time.time()
train(model, train_loader, optimizer)
train_loss, train_acc = evaluate(model, train_loader)
val_loss, val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_acc = val_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print(f"------------------------------------- epoch {epoch} -------------------------------------")
print("train Loss : {:.4f}, Accuracy : {:.2f}%".format(train_loss, train_acc))
print("val_Loss : {:.4f}, Accuracy : {:.2f}%".format(val_loss, val_acc))
print("Completed in {:.0f}m {:.0f}s".format(time_elapsed//60, time_elapsed % 60))
model.load_state_dict(best_model_wts) # 가장 정확도 높은 모델 반환
return model
base = train_baseline(model, train_loader, val_loader, optimizer, epoch)
torch.save(base, "baseline.pt")-> for문을 배치 단위로 돌려서 값들을 뽑는게 합리적이라는 생각이 듬(너무 당연한가.....?)
5. 결과는??
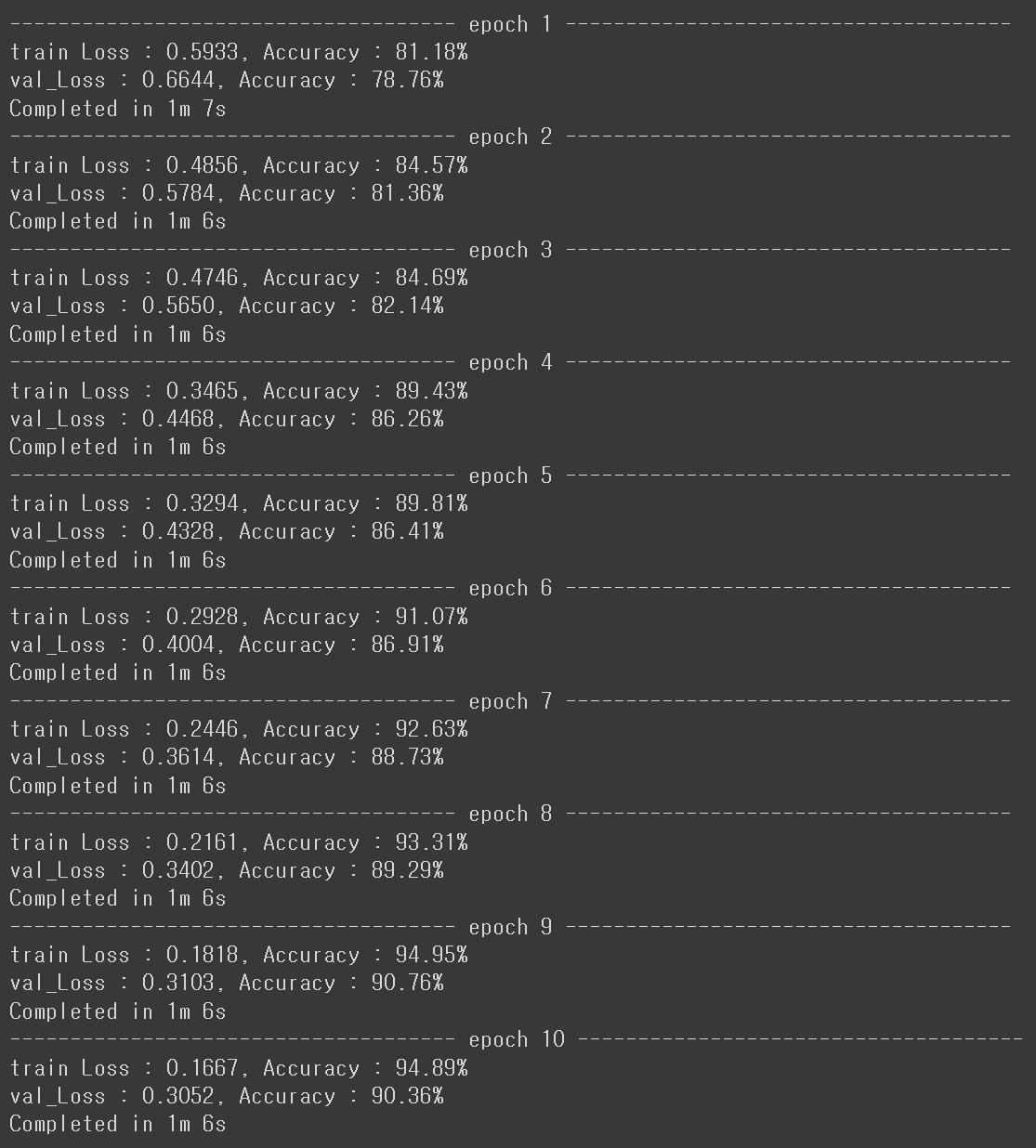
-> Pre_trained 모델도 아닌데 첫 에폭의 검증 점수도 꽤 높게 나온 듯
-> 최종 에폭에서 검증 loss = 0.3052에 검증데이터 정확도 = 90.36%
반응형
'AI_basic > Pytorch' 카테고리의 다른 글
| [Pytorch] 작물 잎 분류 Pre-trained model(resnet50) (1) | 2022.02.07 |
|---|---|
| [Pytorch Part.5] Augmentation과 CNN (1) | 2022.01.14 |
| [Pytorch Part.4] AutoEncoder (2) | 2022.01.14 |
| [Pytorch Part.2] AI Background (0) | 2022.01.06 |
| [Pytorch Part.1] Basic Skill (0) | 2022.01.05 |



