1. 데이터 전처리
폴더 구성은 이전 글의 base model과 같고, 이미 학습된 resnet 모델을 불러옵니다
import torch
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
import os
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
batch_size = 256
epoch = 30
data_transforms = {
"train" : transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomHorizontalFlip(), # base model과 다르게 augmentation을 적용하는데,
transforms.RandomVerticalFlip(), # pre_trained model이라 데이터 양을 더 늘린 것 같음(자료에 이유가 안 나와있다..)
transforms.RandomCrop(52), # 이미지 일부를 52*52로 잘라내어씀
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], # 정규화에 쓰일 각 채널의 평균값
[0.229, 0.224, 0.225]) # 정규화에 쓰일 각 채널의 표준편차값
]),
"val" : transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
}
data_dir = path + "/splitted"
dataset = {x : ImageFolder(root = os.path.join(data_dir, x), transform = data_transforms[x]) for x in ["train", "val"]}
loader = {x : torch.utils.data.DataLoader(dataset[x], batch_size = batch_size, shuffle = True, num_workers = 4) for x in ["train", "val"]}
dataset_sizes = {x : len(dataset[x]) for x in ["train", "val"]}
class_names = dataset["train"].classes-> base model과 데이터 전처리를 다르게 해주는데, Augmentation을 통해 pre-trained모델에 들어갈 데이터를 증강
-> transforms 정규화 부분에서 평균과 표준편차값은 모델의 학습에 사용된 ImageNet 데이터의 값!!
2. pre-trained model 불러오기
from torchvision import models
resnet = models.resnet50(pretrained = True) # False가 되면 모델의 구조만 가져오고 초깃값은 랜덤 설정
num_ftrs = resnet.fc.in_features # fc는 모델의 마지막 layer를, in_features는 해당 층의 입력 채널 수 반환
resnet.fc = nn.Linear(num_ftrs, 33) # 마지막 fc층의 출력 채널을 클래스 수에 맞게 변환
resnet = resnet.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p : p.requires_grad, resnet.parameters()), lr=0.001)
# filter와 lambda를 통해 requires_grad=True인 layer만 파라미터 업데이트
from torch.optim import lr_scheduler
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size = 7, gamma = 0.1)
# 에폭에 따라 lr변경 -> 7에폭마다 0.1씩 곱해짐-> 모델을 불러오는 부분은 큰 어려움 없음
-> 모델의 마지막 출력을 해당 데이터셋 클래스 개수에 맞게 변환해주는게 중요
ct = 0
for child in resnet.children(): # model.children() -> 모델의 layer정보
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False
3. 모델 학습 및 평가 한 번에
def train_resnet(model, criterion, optimizer, scheduler, num_epochs = 25):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0
for epoch in range(num_epochs): # 에폭마다 for문
print(f"---------- epoch {epoch + 1} ----------")
since = time.time()
for phase in ["train", "val"]: # train과 val데이터 동시에-> for문인거 신경 안써도됨
if phase == "train":
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in loader[phase]: # 배치단위마다 for문
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
x, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == "train":
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0) # 교차엔트로피 계산 deafualt값이 mean이므로 각 데이터 마다의 손실 평균이 저장되있음
# 따라서 배치 사이즈를 곱해줘 한 배치 사이즈의 loss 총합을 계산!
running_corrects += torch.sum(preds == labels.data) # -----------------여기까진 base model과 구조가 동일----------------------------
if phase == "train":
scheduler.step()
l_r = [x["lr"] for x in optimizer_ft.param_groups]
print("learning rate : ", l_r)
epoch_loss = running_loss/dataset_sizes[phase] # 전체 데이터 loss합을 각 데이터셋 전체 크기로 나눠주어 loss계산
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print("{} Loss: {:4f} Acc: {:.4f}".format(phase, epoch_loss, epoch_acc))
if phase == "val" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print("Completed in {:.0f}m {:0f}s".format(time_elapsed // 60, time_elapsed % 60))
print("Best val Acc: {:.4f}".format(best_acc))
model.load_state_dict(best_model_wts)
return model-> base 모델에 적용한 함수와 차이점은 스케쥴러가 추가된 모습인데, 이를 제외하면 사실 학습 함수와 평가 함수를 합쳐논 꼴
model_resnet50 = train_resnet(resnet, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=epoch)
torch.save(model_resnet50, "resnet50.pt")
4. 학습, 검증 데이터셋 학습및 평가 결과

-> 최종 에폭에서 train 정확도 99% val 정확도 98%로 base model보다 많이 향상되었다.
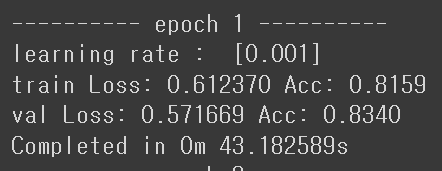
-> 내가 주목한 부분은 첫 에폭인데, pre-trained가 가중치 initialization의 개념이라 첫 평가지표부터 높게 나올 줄 알았는데, base model 첫 에폭 결과가 train 정확도 81% val 정확도 78%인 것에 비해 크게 향상되지 않은 느낌이 들었다.

-> 이 때 두 번째 에폭을 봤는데, base model의 최종 에폭보다 val 정확도가 높다.
-> 첫 에폭은 크게 향상되지 않았으나 두 번째 학습에서 폭발적으로 정확도 증가
-> 이 현상에 대해 두 가지 가정을 내리고 더 알아볼 것으로 추가
1. adam optimizer를 스케쥴러를 통해 lr을 조절한 것이 영향을 주었다.
2. pre-trained 모델의 가중치 초깃값은 이 데이터셋에 랜덤 초깃값보다 맞지 않았으나,
손실함수에서 경사하강법에 더 유리한 위치에 있었다
결과 ++

epoch을 30으로 늘린 결과 val 정확도가 99%까지 증가
6. base model과 pre_trained model test_data평가
1. test 데이터 전처리
test_base = ImageFolder(root = path + "/splitted/test", transform = transform_base)
test_loader_base = torch.utils.data.DataLoader(test_base,
batch_size = batch_size, shuffle = True, num_workers = 4)
trans_resnet = transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
test_resnet = ImageFolder(root = path + "/splitted/test", transform = trans_resnet)
test_loader_resnet = torch.utils.data.DataLoader(test_resnet, batch_size = batch_size, shuffle = True, num_workers = 4)-> test 데이터는 Augmentation 적용 X
2. 각 모델 평가
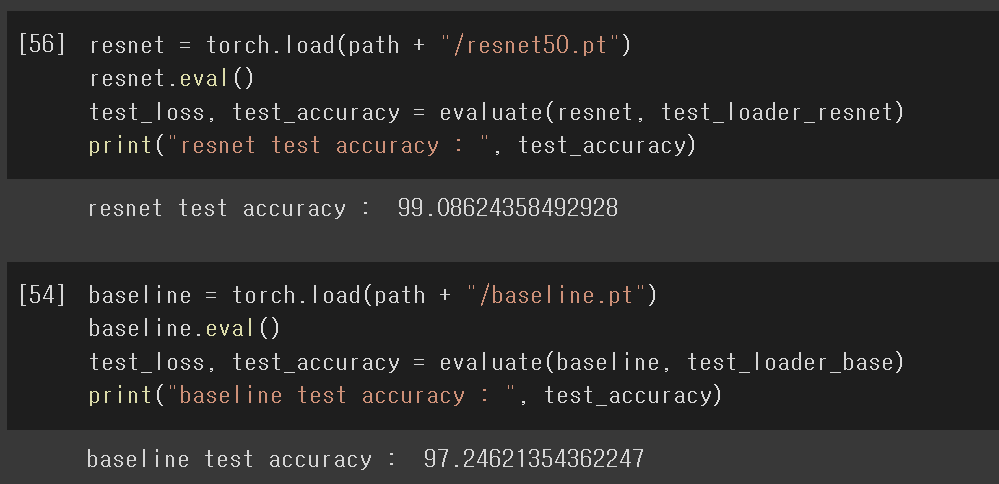
-> base model의 test 데이터 정확도가 높게 나와 당황하여 데이터셋 분할을 다시 확인해봤는데 이상이 없었다...
-> 모든 결과는 알지 못하는 데이터셋과 모델의 차이점으로 생기는 것으로 넘어감
-> 결과적으로 pre_trained 모델이 base model보다 정확도가 더 높게 나옴 약 2%p
'AI_basic > Pytorch' 카테고리의 다른 글
| [Pytorch] 작물 잎 분류 non Pre_trained model (1) | 2022.02.06 |
|---|---|
| [Pytorch Part.5] Augmentation과 CNN (1) | 2022.01.14 |
| [Pytorch Part.4] AutoEncoder (2) | 2022.01.14 |
| [Pytorch Part.2] AI Background (0) | 2022.01.06 |
| [Pytorch Part.1] Basic Skill (0) | 2022.01.05 |



