1. Residual Block
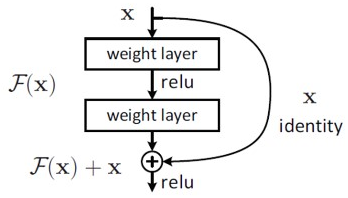
ResNet은 논문에서 Residual Block을 제안하였다. layer를 통과했을 때 Input과 output의 변화는 y = f(x)+x와 같은데, y는 x가 그대로 보존됨으로써 기존에 학습한 정보를 보존하고, 거기에 추가적으로 학습하는 정보를 의미하게 된다. 즉, Output에 이전 레이어에서 학습했던 정보를 연결함으로써 해당 층에서는 추가적으로 학습해야 할 정보만을 Mapping, 학습하게 된다.
y=H(x)라고 할때, 학습이 진행되어 layer의 depth가 깊어질 수록, 즉 학습이 많이 될수록 x는 점점 출력값 H(x)에 근접하게 되어 추가 학습량 F(x)는 점점 작아져서 최종적으로 0에 근접하는 최소값으로 수렴된다.
따라서, H(x)=F(x)+x에서 추가 학습량에 해당하는 F(x)=H(x)−x가 최소값(0)이 되도록 학습이 진행이 된다.
또한, Residual Block이 적용된 모든 각 layer들의 미분값이 f`(x) + 1로 최솟값 1을 갖기 때문에 gradient vanishing 현상을 보완했다고 볼 수 있다.
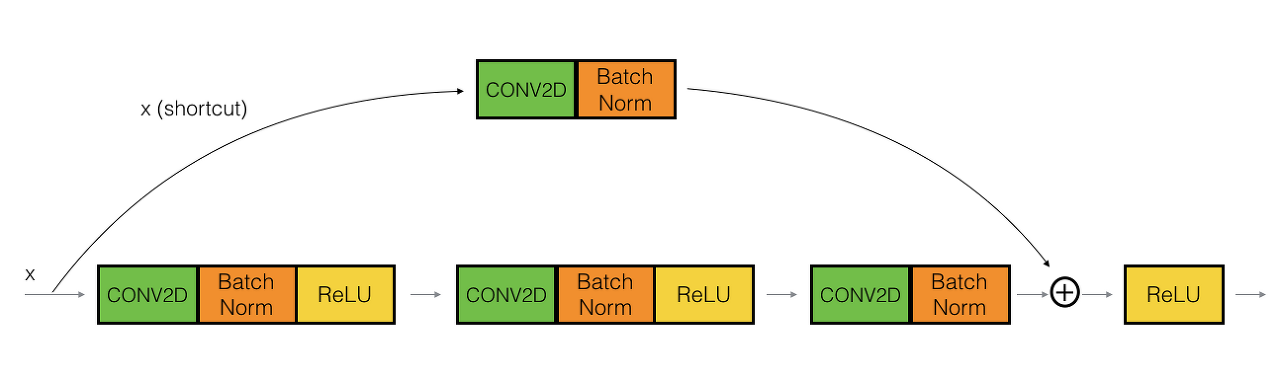
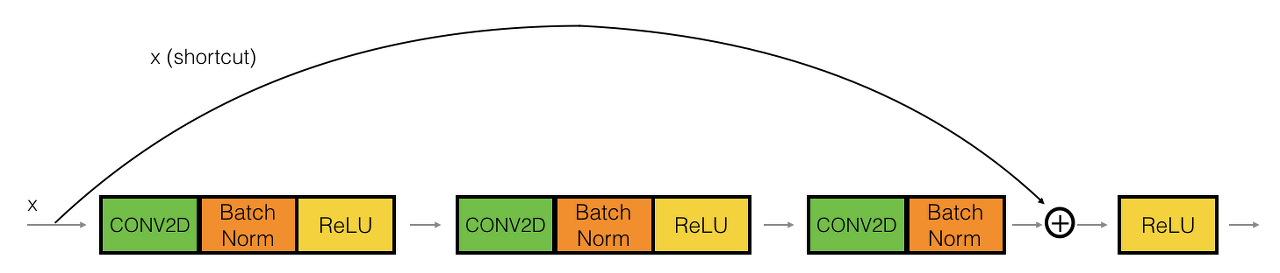
Residual Block에서 input x를 output에 연결해주는 것을 shortcut(지름길)이라고 하는데, 두 가지 방식이 있다. 첫번째 Convolution block같은 경우 1X1 Convolution연산을 거친 후 F(x)에 더해주고, Identity block 같은 경우 x를 그대로 전달해 더해준다.
코드 상에서는 각 layer stage 별 첫 번째 layer가 Convolution block이 되도록 설계가 되어있다.
2. Bottleneck
차원을 줄였다 늘리는 모습이 병목처럼 보여 Bottleneck이라는 이름이 붙었다. Bottleneck이 제안된 이유는 연산 시간을 줄이기 위함이다. 차례대로 1x1, 3X3, 1X1 사이즈의 세 Convolution layer로 구성되어있다.
첫 1X1 Convolution연산은 차원을 줄이기 위함이다. 이렇게 차원을 줄인 후 3X3 Convolution 연산을 실행하고, 다시 1X1 Convolution연산을 적용해 차원을 늘린다. (3.구조의 table에서 parameter 확인가능)
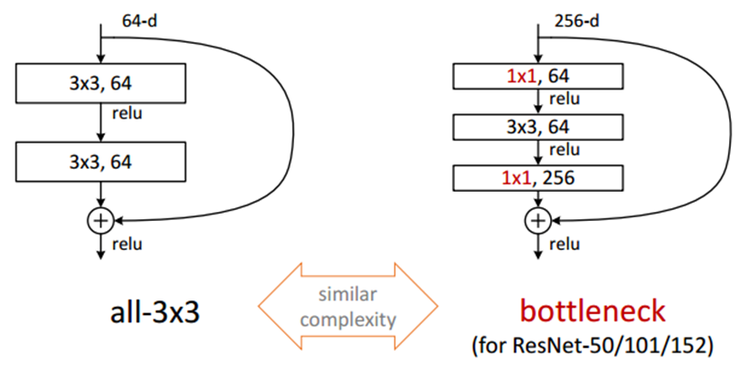
Bottleneck이 주는 장점은 적은 파라미터 개수로 인한 연산 시간 축소이다. 3X3 Convolution연산을 두번 적용한 왼쪽그림과 비교해 오른쪽의 Bottleneck Block은 연산량을 더 절감할 수 있다.
- Bottleneck 사용 X : 3×3×64×2=1152
- Bottleneck 사용 O : (1×1×64)+(3×3×64)+(1×1×256)=896 (약 22% 절감)
3. 전체 구조
ResNet은 기본적으로 VGG-19를 뼈대로 convolution layer들을 추가해 깊이 만들고, shortcut을 추가하는 것이 사실상 전부다.
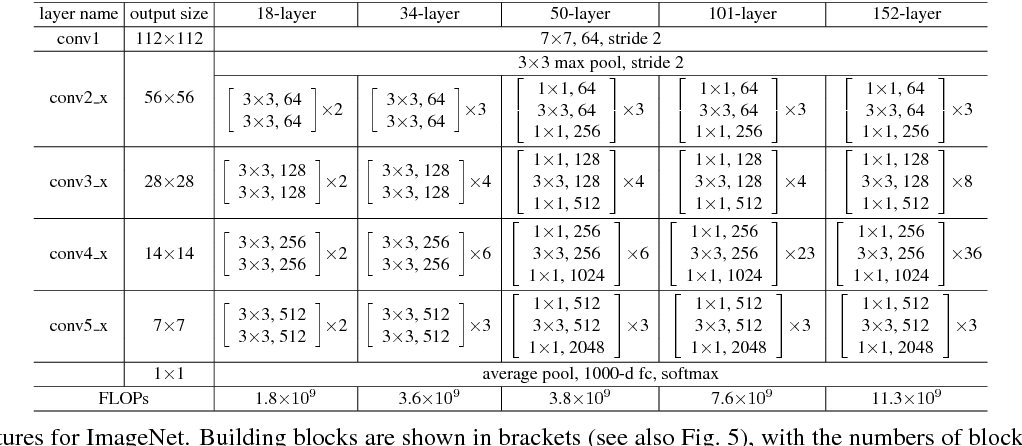
위 table에 나와있듯이, 각 layer-version마다 layer의 개수와 block의 종류(Basic block, bottleneck block)이 다르다.
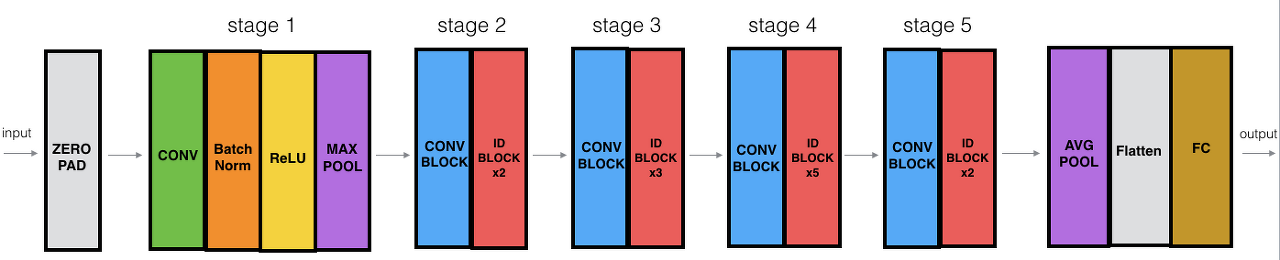
기본적인 구조는 위와 같다. layer-version에 따라서 stage2~stage5의 각 layer 개수가 결정된다.
import torch
import torch.nn as nn
import torch.nn.functional as F # 필요모듈 import
class BasicBlock(nn.Module): # identity block
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d( # 1번 conv layer
in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes) # 첫 번째 batch 정규화
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, # 2번 conv layer
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes) # 두 번째 batch 정규화
# 파라미터를 보면 feature map 크기를 유지하는 것을 알 수 있음
self.shortcut = nn.Sequential() # identity block
if stride != 1 or in_planes != self.expansion*planes: # if문의 이 두 조건은 각 stage별 첫번째 block의 첫번쨰 layer에
# convolution block이 들어가기 위함이다
self.shortcut = nn.Sequential( # convolution block
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # skip connection
out = F.relu(out)
return out
class Bottleneck(nn.Module): # Bottleneck
expansion = 4 # Bottleneck의 input, ouput channel 사이즈 차이
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) # 1번 conv layer
self.bn1 = nn.BatchNorm2d(planes) # 첫 번째 batch 정규화
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, # 2번 conv layer
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes) # 두 번째 batch 정규화
self.conv3 = nn.Conv2d(planes, self.expansion * # 3번 conv layer
planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes) # 세 번째 batch 정규화
self.shortcut = nn.Sequential() # identity block
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential( # convolution block
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x) # skip connection
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64) # 여기까지 block 적용 전 첫 conv layer + batch
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # 각 stage별 파라미터가 다른 conv layer로 구성
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1) # 각 stage별 첫 번째 layer stride는 parameter에 따라, 두 번째부터는 1
layers = [] # num_blocks는 Resnet에 입력된 각 stage별 layer 개수.
for stride in strides: # 18-layer의 경우 [2, 2, 2, 2]로 stage별 2개씩의 layer 생성
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion # 각 stage별 channel width 확장은 block 종류에 따라 결정
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) # 18-layer model로 설명하면, 1번 layer => Conv2d layer X 1
out = self.layer1(out) # 2번 => (3X3,64 Con2d layer X 2) X 2
out = self.layer2(out) # 3번 => (3X3, 128 Con2d layer X 2) X 2
out = self.layer3(out) # 4번 => (3X3, 256 Con2d layer X 2) X 2
out = self.layer4(out) # 5번 => (3X3, 256 Con2d layer X 2) X 2
out = F.avg_pool2d(out, 4) #
out = out.view(out.size(0), -1)
out = self.linear(out) # 6번 => linear layer X 1
return out # 1 + 2X2 + 2X2 + 2X2 + 2X2 + 1 = 18-layer
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def ResNet50():
return ResNet(Bottleneck, [3, 4, 6, 3]) # 50-layer부터 Bottleneck block 적용
def ResNet101():
return ResNet(Bottleneck, [3, 4, 23, 3])
def ResNet152():
return ResNet(Bottleneck, [3, 8, 36, 3])
def test():
net = ResNet18()
y = net(torch.randn(1, 3, 32, 32))
print(y.size())
'DL > basic' 카테고리의 다른 글
| SPPNet (3) | 2024.01.04 |
|---|---|
| GoogLeNet (3) | 2024.01.04 |
| [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (1) | 2022.02.16 |
| [논문리뷰] Attention is all you need (2) | 2022.02.15 |
| [논문리뷰]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (3) | 2022.01.23 |



