전체구조

GoogleNet은 네트워크를 깊게 디자인하면서도 파라미터 수를 줄이면서 Overfitting을 방지하고자했다. 모델이 deep하더라도 연결이 sparse하다면 파라미터 수가 줄어들어 Overfitting을 방지하고, 연산 자체는 Dense하게 하는 것을 목표로 한다.
1. Inception module

Inception module은 1X1, 3X3, 5X5 convolution 연산과 3X3 max pooling을 수행해 feature 효율적으로 추출하고자 한다.
1-1. naive inception

세 개의 convolution 연산을 보면 concat을 위해 feature map 크기를 28X28로 맞추기 위해 패딩값이 설정되어있는 것을 알수 있다. 또한 pooling layer의 경우 채널 수가 유지 되기 때문에(convolutional layer처럼 채널 수 감소시키지 못함) 층이 깊어질수록 채널 수가 많아지게 된다.
1-2 dimension reduced Inception

dimension reduced Inception은 native version과 달리 1X1 convolution 연산을 3X3, 5X5 convolution 연산 전에, max pooling 층 후에 적용시켰다는 것이다. 우선 convolution 연산에서는 같은 Input과 output을 가짐에도 중간에 Dense한 연산을 적용시켜 파라미터 수를 크게 줄였다. Max pooling layer의 경우 채널 수를 변화시키지 못한다는 점을 1X1 연산을 통해 feature map크기는 유지하면서 채널 수에 변화를 줄 수 있었다.
2. Global Average Pooling
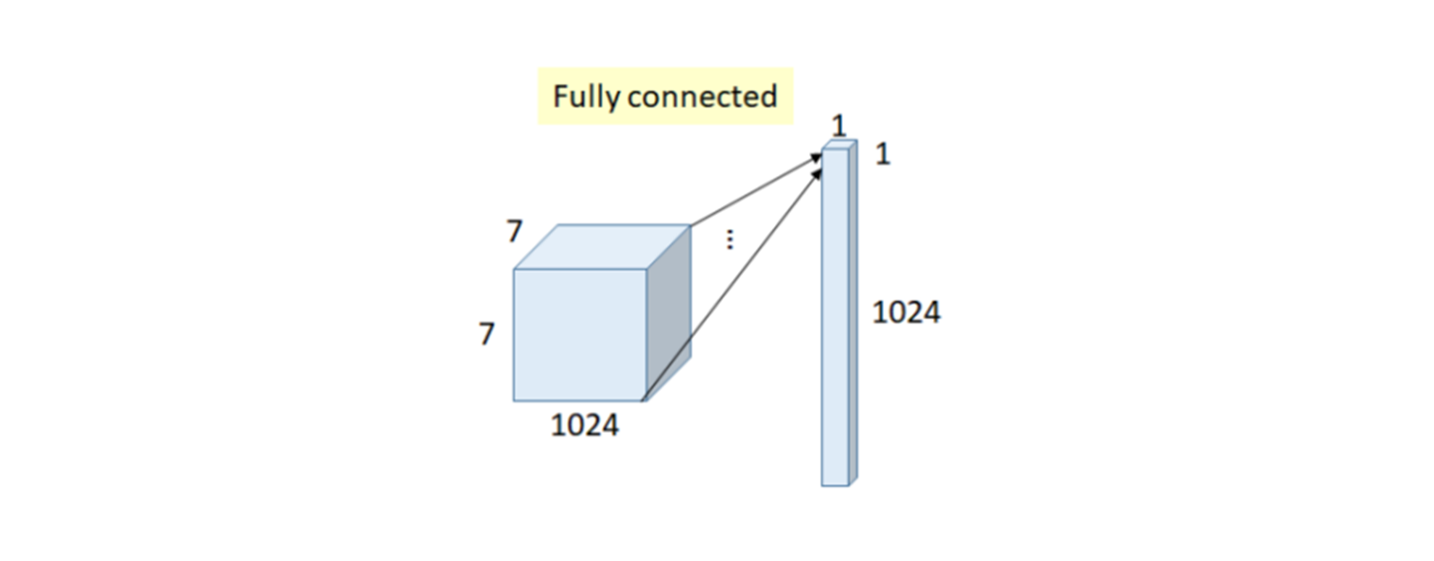
기존 CNN모델들은 분류 등의 task를 위해 마지막에 softmax함수를 취하기 위해 feature map을 flatten한 뒤 Fully connected layer를 적용하는 방식을 사용했는데, 이는 feature map의 공간적 정보를 잃어버리고, 많은 파라미터를 사용하게 된다. 이를 극복하기 위해 Global Average Pooling가 제안되었다.

Global Average Pooling은 이전 계층의 output이 7X7X1024일 때, 채널별 feature map의 특징값들을 평균하여 1024개의 값을 만들어내고, 이를 바로 출력노드에 연결시킨다. 이 경우 평균이라는 계산을 통해 파라미터 수가 0이 된다.
3. Auxiliary Classifier
이전의 CNN계열 모델에서는, 모델이 깊어질수록 gradient vanishing 문제가 생긴다. GoogleNet의 경우 층의 중간에 Auxiliary Classifier라는 것을 추가해 모델의 중간에서도 Backpropagation이 가능하게하여 이 문제를 해결하고자했다.
이 때 weight에 큰 영향을 주는 것을 막기 위해 Auxiliary Classifier에 0.3을 곱한다. 또한 Backpropagation을 위해 만든 분류기인만큼 검증수행시에는 제거한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Inception(nn.Module):
def __init__(self, in_planes, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes):
# red같은 경우 reduction을 의미하며, 각 conv연산에 들어가기 전
# 1x1 conv연산의 output 채널을 의미한다.
super(Inception, self).__init__()
# 1x1 conv branch
# Inception module에서 1x1 conv연산 단일 층
self.b1 = nn.Sequential(
nn.Conv2d(in_planes, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(True),
)
# 1x1 conv -> 3x3 conv branch
# Inception module에서 1x1 conv연산 후 3x3 conv연산 sequential
self.b2 = nn.Sequential(
nn.Conv2d(in_planes, n3x3red, kernel_size=1),
nn.BatchNorm2d(n3x3red),
nn.ReLU(True),
nn.Conv2d(n3x3red, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(True),
)
# 1x1 conv -> 5x5 conv branch
# Inception module에서 1x1 conv연산 후 5x5 conv연산 sequential
self.b3 = nn.Sequential(
nn.Conv2d(in_planes, n5x5red, kernel_size=1),
nn.BatchNorm2d(n5x5red),
nn.ReLU(True),
nn.Conv2d(n5x5red, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
)
# 3x3 pool -> 1x1 conv branch
# maxpooling layer
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(in_planes, pool_planes, kernel_size=1),
nn.BatchNorm2d(pool_planes),
nn.ReLU(True),
)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3(x)
y4 = self.b4(x)
return torch.cat([y1,y2,y3,y4], 1) # 채널 차원으로 concat(feature map들을 채널 차원 축의 방향으로 이어붙힌 형태)
class GoogLeNet(nn.Module):
def __init__(self, num_classes = 10 ):
super(GoogLeNet, self).__init__()
self.num_classes = num_classes
self.pre_layers = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(True),
)
# Inception module의 parameter가 헷갈릴 수 있는데, 1, 3, 5, 6번째 parameter가 각 conv연산의 output채널이며,
# 이 파라미터들의 합이 다음 Inception 모듈의 input 채널이 되는 것을 알 수 있다.
# layer 이름 끝에 붙은 인덱스(3, 4, 5)별로 feature map의 크기는 28x28, 14x14, 7x7이다.
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(8, stride=1)
self.linear = nn.Linear(1024, num_classes)
def forward(self, x):
out = self.pre_layers(x)
out = self.a3(out)
out = self.b3(out)
out = self.maxpool(out)
out = self.a4(out)
out = self.b4(out)
out = self.c4(out)
out = self.d4(out)
out = self.e4(out)
out = self.maxpool(out)
out = self.a5(out)
out = self.b5(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1) # Global Average Pooling 적용 후 FC-layer에 적용하기 위해 전치
out = self.linear(out)
return out'DL > basic' 카테고리의 다른 글
| DenseNet (3) | 2024.01.04 |
|---|---|
| SPPNet (3) | 2024.01.04 |
| ResNet (3) | 2024.01.04 |
| [논문리뷰] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (1) | 2022.02.16 |
| [논문리뷰] Attention is all you need (2) | 2022.02.15 |



