Main ideas

1) 1-stage detector
https://2021-01-06getstarted.tistory.com/74
R-CNN
Introduction cv에서의 주요 task에 대한 설명은 다음과 같다. Classification : Single obeject에 대해서 object의 클래스를 분류하는 문제. Classification + Localization : Single object에 대해서 object의 위치를 bounding box
2021-01-06getstarted.tistory.com
- R-CNN과 달리 YOLO v1은 별도의 region proposals를 사용하지 않고 전체 이미지를 사용한다.
- 전체 이미지를 SXS 크기의 grid로 나눠준다.
- 객체의 중심이 특정 grid cell에 있다면 해당 grid cell은 그 객체를 인식하도록 할당한다.
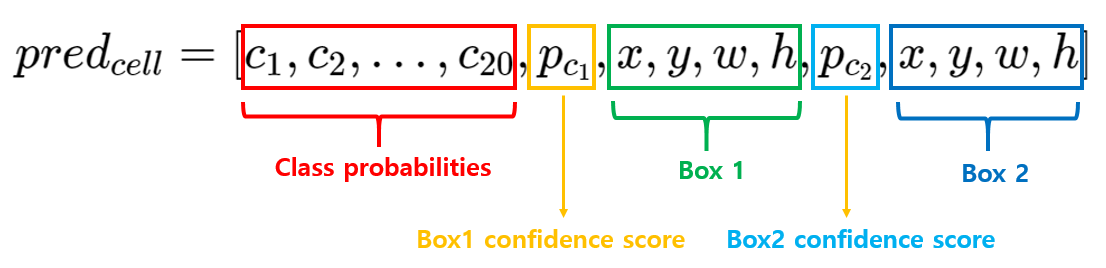
- 각각의 grid cell은 B개의 bounding box와 해당 box에 대한 confidence score(객체여부 X IoU)를 예측한다.
- 각각의 bounding box는 좌표정보(x, y, w, h)와 confidence score라는 5개의 output을 산출한다.
- 하나의 bounding box는 하나의 객체만을 예측하며, grid cell은 하나의 bounding box를 학습에 사용한다.
- grid cell별로 B개의 bounding box를 예측할 때, confidence score가 가장 높은 1개의 bounding box만 학습에 사용한다.
- 각 grid cell은 C개의 조건부 확률(grid cell에 객체가 존재한다고 가정할 때, 특정 class일 확률)을 예측한다. (PASCAL VOC classes=20) (Bounding box가 아닌 grid cell 별로 class probabilities 예측)
- 논문에서 S=7, B=2, C=20으로 설정했다.(이미지별 예측값의 크기는 7x7x(2x5+20) -> box 좌표정보 + confidence score는 box별 output이라 2x5지만, class probabilites는 grid cell당 이라 한 grid cell의 output은 2x5 + 20개)
2) DarkNet

DarkNet은 YOLO v1 모델이 feature map을 생성하기 위해 만들어진 독자적인 Convolutional Network이다.
DarkNet은 ImageNet을 학습시킨 뒤(top-5 88%) detection을 위한 4개의 conv layer와 2개의 fc layer를 추가한다. 또한 ImageNet 학습 시에 224x224사이즈 이미지를 사용하고, detection task를 위한 학습에는 448x448 사이즈의 이미지를 사용한다.
3) Loss function
1. Localization Loss

더 많은 grid cell은 객체를 포함하지 않아 confidence score가 0이다. 따라서 grid cell의 gradient를 압도하여 모델이 불안정해질 수 있다. 이 부분을 보완하기 위해 객체를 포함하는 cell에 가중치를 둔다()
위 수식에서 두 항을 묶어줄 수 있지 않나 싶었는데, 자세히 보면 x, y와 달리 w, h에는 루트가 씌어져 있다. 이는 크기가 큰(w, h가 큰) bounding box의 작은 오류가 크기가 작은 bounding box의 오류보다 덜 중요하다는 것을 반영하기 위해서다.
2. Confidence loss

객체를 포함하지 않는 경우 가중치()를 설정하여 객체를 포함하지 않는 grid cell의 영향력을 줄인다. 위 두 항은 객체 포함 여부에 따라 한 항만 남게 되며, 객체가 있는 경우의 가중치는 1인 것을 해석된다.
3. Classification loss

Training

우선 DarkNet으로 7x7x30 사이즈의 feature map을 만들고, 위에서 정의한 Loss function을 통해 학습한다. 끝!
Detection
학습 외 최종 output에 NMS 알고리즘을 적용하고, 이를 통해 mAP 값이 2~3%정도 향상된다고 한다.
Performance
1. VOC 2007 Error Analysis
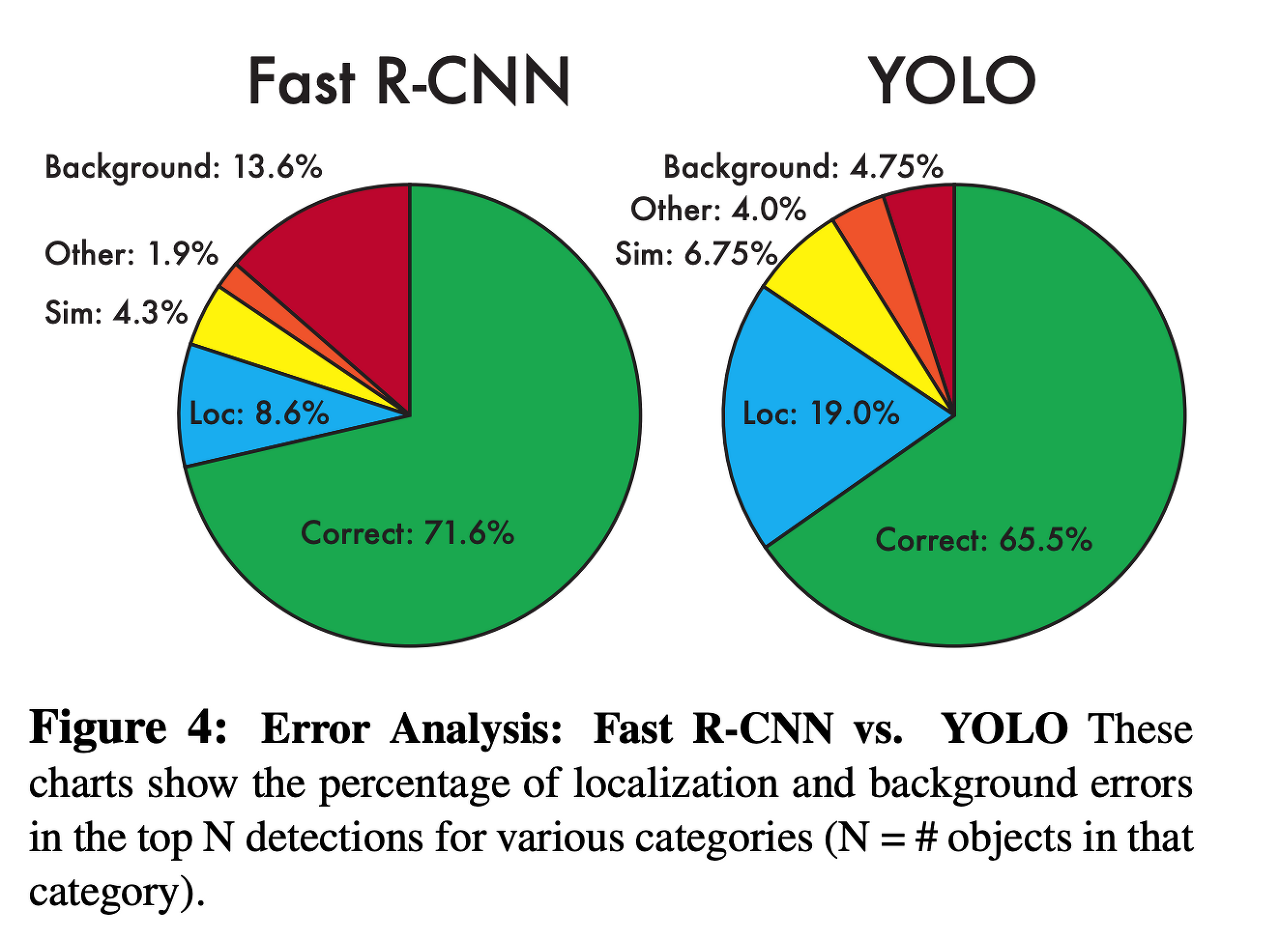
- Correct : 물체를 맞추고 , IOU값도 0.5 보다 큼
- Localization : 물체는 맞췄으나 IOU값이 0.1 부터 0.5사이
- Similar : 클래스가 유사함, IOU값도 0.1 이상
- Other : 클래스가 틀리고 IOU값은 0.1 이상
- Background Error : IOU값이 0.1 이하.
YOLO v1의 Background Error가 Fast R-CNN에 비해 3배나 적지만, 물체를 정확히 예측하는 Localization Error는 YOLO가 더 많다.
2. FPS mAP
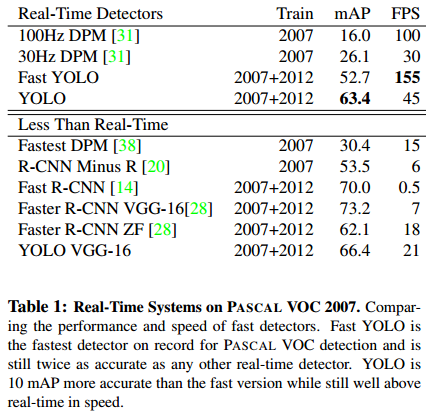
실시간 객체 탐지를 위해서는 초당 30프레임=30FPS 이상 나와야 한다고 논문 저자는 말하는데, YOLO는 Fast가 아닌 버전에서도 그 요건을 충족시키고, VGG-16과 결합 모델에서도 21FPS를 보여준다. 다만 2-stage detection 모델들에 비해 mAP는 다소 떨어지는 모습이다
한계점
- 공간적 제약으로 하나의 grid cell은 2개의 bounding box 예측이 가능하지만 하나의 class에 대한 예측만 진행한다. 따라서 작은 물체가 여러 개 있을 시 예측이 어렵다.
- data에 대한 bounding box를 학습하기 때문에 다양한 종횡비나 배열에 대한 예측이 어렵다.(bounding box shape이 단순)
'DL > Object detection' 카테고리의 다른 글
| FPN (Feature Pyramid Networks for Object Detection) (0) | 2024.01.17 |
|---|---|
| YOLO v2 (1) | 2024.01.15 |
| Faster R-CNN (1) | 2024.01.05 |
| Fast R-CNN (0) | 2024.01.05 |
| R-CNN (0) | 2024.01.05 |



