FPN
다양한 크기의 객체를 인식하는 것이 OD task의 핵심적인 문제이다. 기존의 방식대로면 모델의 추론 속도가 너무 느리며 메모리를 지나치게 많이 사용했다. FPN은 이를 통해 컴퓨팅 자원을 적게 차지하면서 다양한 크기의 객체를 인식하는 방법을 제시한다.
Summary

원본 이미지를 Conv layer에 입력해 Forward pass를 진행하고, 각 stage마다 다른 scale을 가지는 4개의 Feature map을 추출한다. 이 과정을 Bottom-up pathway라고 하는데, 후에 Top-down pathway를 통해 각 feature map에 1x1 conv layer를 적용해 모두 256개의 channel을 가지도록 조정하고 Upsampling을 진행한다. 마지막으로 Lateral connections 과정을 통해 pytamid level 바로 아래 있는 Feature map과 element-wise addition 연산을 수행한다. 이를 통해 얻은 4개의 서로 다른 Feature map에 3x3 conv layer 연산을 적용한다.
Main ideas

논문에서 언급하는 Pyramid는 conv layer에서 얻을 수 있는 다른 해상도의 Feature map들을 쌓아올린 형태라고 생각하면 된다. 그리고 Level은 각 피라미드 층에 해당하는 feature map이라고 생각하면된다.

convolutional network에서는 입력층에 가까울 수록 feature map은 높은 해상도를 가지고, 가장자리, 곡선 등과 같은 Low-level feature를 보유한다. 반대로 더 깊은 층에서 얻을 수 있는 feature map은 낮은 해상도를 가지며 질감과 물체의 일부분 등 class를 추론할 수 있는 high-level feature를 가지고 있다.
Object detection 모델은 feature map의 일부 혹인 전부를 사용하여 예측을 수행한다.
기존 방식
다양한 크기의 객체를 인식하도록 모델을 학습시키기 위해 다양한 시도가 있었다.

a. Featurized image pyramid
입력 이미지의 크기를 Resize하여 다양한 크기의 이미지를 네트워크에 입력한다. 다양한 크기의 객체를 포착하는데 좋은 결과를 보여주지만, 이미지 한 장을 독립적으로 모델에 입력해 feature map을 생성하기 때문에 추론속도가 매우 느리며 메모리를 많이 차지한다.
b. Single feature map
단일 크기의 입력 이미지를 활용해 feature map을 얻는 방식으로, YOLO v1모델이 그렇다. 학습 및 추론속도가 매우 빠르지만 성능이 떨어진다.
c. Pyramidal feature hierachy
네트워크에서 미리 지정한 conv layer마다 feature map을 추출해 예측하는 방법이다. SSD 모델이 사용했다. multi-scale feature map을 사용해 성능이 높지만 featre map 간 해상도 차이로 인해 학습하는 representation에서 차이인 semantic gap이 발생한다. SSD 모델은 해당 문제를 보완하기 위해 전체 network에서 중간 지점부터 Feature map을 추출하는데, FPN 저자들은 low-level feature는 작은 객체를 인식할 때 유용하기 때문에 이를 제외하는 것은 적절하지 않다고 한다.
d. Feature Pyramid Network

FPN은 새롭게 설계된 모델이 아니라 기존 convolutional network에서 지정한 Layer별로 feature map을 추출하여 수정하는 네트워크라고 이해하면 된다. 논문에서는 ResNet을 사용한다. FPN이 feature map의 Pyramid를 쌓아올리는 과정은 bottom-up pathway, top-down pathway, lateral connections에 따라 진행된다.
Bottom-up pathway

Bottom-up pathway 과정은 network의 forward pass 시 2배씩 작아지는 Feature map을 추출하는 과정이다. 이 때 각 stage 마지막 Layer의 output feature map을 추출한다. 논문에서는 같은 크기의 feature map을 출력하는 layer는 같은 stage에 있다고 정의하는데, 같은 stage 내에서는 마지막 layer(깊을 수록)가 더 강력한 Feature를 보유해 이를 pyramid level로 지정하기 때문이다.
FPN은 ResNet의 각 Stage 마지막 residual block의 output feature map을 활용해 Pyramid를 구성한다. 이 때 각 outputdmf {c2, c3, c4, c5}라고 지정하고 각각 {4, 8, 16, 32} stride를 가진다. conv1의 feature map은 많은 메모리를 차지하기 때문에 제외되었다고 한다.
Top-down pathway & Lateral connections
Top-down pathway는 각 level에 있는 feature map을 2배로 upsampling하고 channel 수를 동일하게 맞춰주는 과정이다. 이 때 upsampling은 nearest neighbor umpsampling 방식을 사용한다. 이 때 모든 pyramid level이 동일하게 umsapling되면 아래의 level과 다른 사이즈가 되는데, 아래와 같은 Lateral connection을 통해 각각의 umsampling된 level을 아래층의 level과 결합시켜준다.
이 때 {c2, c3, c4, c5}는 {p2, p3, p4, p5}로 변환된다. 이 때 c2 같은 경우 아래층이 없기 때문에 그대로 1x1 conv 연산만을 거치고 p2를 얻는다.
Top-down pathway에서 높은 층의 Level은 공간적으로 coarser하지만 의미적으로 stronger한데, 이를 Umpsamling 함으로써 high-level feature에 hallucinates를 일으킨다. 하지만 lateral connection을 통해 보완된다.


FPN은 sing-scale 이미지를 입력하기 때문에 a 방식에 비해 빠르고 메모리를 덜 차지하고, multi-scale feature map을 출력하기 때문에 b 방식보다 높은 성능을 보여준다.
또한 여러 Level을 feature map을 결합해 사용함으로 low-level feature를 제외한 c 방식 보다 작은 객체를 더 잘 인식한다.(lov-level feature는 객체의 위치에 대한 정보를 상대적으로 정확하게 보존하기 때문.)
a~d 이외에 d와 유사한 방식인 (e)는 FPN이 등장할 시기의 최신모델들이 사용한 방법인데, FPN과 비슷하게 top-dwon방식을 이용하고 feature map을 연결시키기 위해 skip connection을 사용하지만 마지막 stage에서만 predict를 수행한다는 차이점이 있다.
Training ResNet + Faster R-CNN with FPN
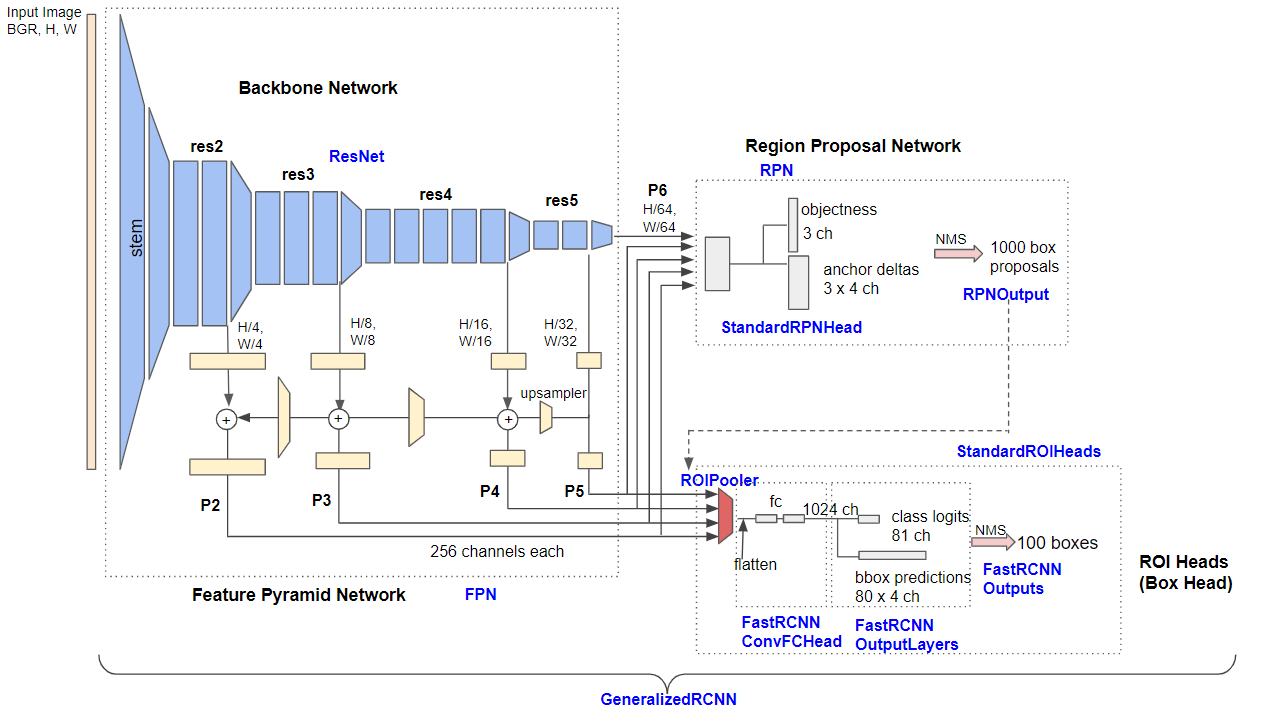
1. Build Feature Pyramid by FPN
ResNet 기반의 FPN으로 Lateral connection을 거쳐 {p2, p3, p4, p5}을 출력한다. 이 후 네 feature map은 RPN과 pooling 시 사용된다.
2. Class score and Bounding box by RPN
앞의 과정에서 얻은 Feature ma들을 RPN(Region Proposal Network)에 입력한다. 이 때의 결과값인 class score와 bounding box regressor는 각 feature map별로 추출하고, 이후 NMS(Non Maximum Suppression)을 적용해 class socre가 높은 상위 1000개의 region proposal만 출력한다.
3. Max pooling by RoI pooling
1의 과정에서 얻은 multi-scael feature maps와 2번 과정에서 얻은 1000개의 region proposals를 사용해 RoI pooling을 수행한다. FPN을 적용한 Faster R-CNN은 오리지널과 달리 multi-scale feature map을 사용하기 때문에 region proposals를 어떤 scale의 feature map과 매칭시킬지를 결정해야한다.

논문에서는 위 공식에 따라 region proposal을 K번째 Feature map과 매칭시킨다. w, h는 RoI의 것에 해당하며 k는 Pyramid level의 Index, k0는 target level을 의미한다. 논문에서는 k0=4로 설정했는데, 직관적으로 RoI의 scale이 작아질수록 낮은 pyramid level, 즉 더 작은 객체를 잘 인식할 수 있는 low-level feature map에 할당하고 있습니다. 이 과정을 통해 고정된 크기의 Feature map을 얻을 수 있다.
4. Train Faster R-CNN
위 과정들을 거쳐 얻은 고정된 크기의 feature map을 Faster R-CNN에 입력한 후 multi-task loss function을 통해 학습시킨다.
5. Detection
실제 추론 시 Faster R-CNN의 마지막 예측에 Non maximum suppression을 적용해 최적의 예측 결과만을 출력한다.
Conclusion
ResNet을 backbone network로 사용해 Faster R-CNN에 FPN을 결합시켰을 때, FPN을 사용하지 않았을 경우보다 AP rkqtdl 8% 이상 향상됐다. 이외에도 FPN은 end-to-end 모델에 그대로 적용이 가능하며 학습 및 테스트 시간이 일정하여 메모리 사용량이 적다는 장점을 보였다.
'DL > Object detection' 카테고리의 다른 글
| [논문 리뷰] Object Detection in 20 Years: A Survey (0) | 2024.01.19 |
|---|---|
| Mask R-CNN (0) | 2024.01.18 |
| YOLO v2 (1) | 2024.01.15 |
| YOLO v1 (1) | 2024.01.05 |
| Faster R-CNN (1) | 2024.01.05 |



