조금 지난 것이지만 Object detection의 역사를 전반적으로 이해할 수 있는 Survey 논문에 대한 리뷰인데, Survey 논문의 특성상 구석구석 읽어봐야겠다는 생각으로 요약보다는 생략에 초점을 두었다. 따라서 리뷰보다는 번역과 생략이라고 할 수 있다!!
Introduction
Object detection은 사람, 동물, 차와 같은 객체들의 class를 인식하는 CV의 중요한 task이다. Object detection의 목표는 어떠한 객체가 있는지?를 계산하는 모델 및 기술을 개발하는 것이다. Object detection의 주요한 두 지표는 정확도와 속도이다.
Object detection은 Instacne segmentation과 같은 다른 CV task를 위한 기초이다. 최근 딥러닝 기술의 발전으로 Object detection 또한 발전해왔다. Object detection은 자율주행, 로봇 비전, 비디오 감시와 같은 현실적인 분야에서 널리 사용되고 있다.

CV task들에서는 다른 시점의 객체, 조명 및 클래스 내 변화와 같은 어려움이 있는데, Object detection은 이에 국한되지 않고 객체의 회전 및 스케일 변경, 정확한 객체 위치 지정, 탐지 속도 등의 어려움이 있다. Sector 4에서 이러한 주제에 대한 자세한 분석을 제공할 것이다.
이 Survey는 초보자들에게 Object detection 기술의 발전을 중점에 두고 다양한 관점에서 파악할 수 있도록 한다. 주요 특징은 기술 발전에 관점을 둔 종합적인 검토, 주요 기술 및 최신 기술 상태에 대한 심층적인 탐구, 감지 속도 향상 기술에 대한 종합적인 분석이다. 여기서의 주된 정보들은 dataset, metrics, 가속 기술과 같은 Obeject detection에 필요한 다른 요소들의 과거, 현재 및 미래이다. 이 Suvey는 기술적 세부사항은 생략하고 독자들이 필수 개념을 이해하고 잠재적인 미래 방향을 찾을 수 있도록 기술 발전을 설명하는 것을 목표로 한다.
2. Obeject Detection In 20 Years

A. A Road Map of Object Detection
지난 20년간의 Object detection은 2014년을 기점으로 전통적인 Object detection 기법과 딥러닝을 기반으로 한 Object detection 기법들로 기간이 나뉜다. 여기서 traditional Object detection 기법의 요약은 생략한다.
1) CNN based Two-stage Detectors
2012년 CNN network가 robust한 학습과 high-level feature representations 학습이 가능해졌고, 이것을 Object detection에 사용할 수 있느냐는 질문으로 이어진다. 여기서 RCNN이 제안되었고, 여기서 two-stage detector와 one-stage detector 두 그룹으로 나뉜다.
RCNN - RCNN의 아이디어는 심플한데, selective search를 사용해 object proposals를 추출하는 것으로 시작한다. 그리고 각 proposals는 고정된 사이즈로 rescale된 뒤 CNN pretrained model에 입력된다. 최종적으로, linear SVM classifiers가 각 영역 내 Object가 존재여부를 예측하고 범주를 인식한다. RCNN은 큰 발전을 이루었지만 region들이 많이 중복된 계산으로 추론 속도가 느리다는 단점이 있다.
SPPNet - 2014년 Spatial pyramid Pooling network가 제안되었는데, SPP계층의 도입으로 CNN network는 이미지와 영역의 크기에 관계없이 rescaling없는 고정 길이의 representation을 생성할 수 있게 된다. SPPNet을 사용할 경우 전체 이미지에서 feature map을 한 번만 계산해도 detetor training을 위한 고정된 사이즈의 feature를 생성할 수 있어 RCNN에 비해 계산량이 줄어든다. SPPNet은 Detect 정확도를 유지하며 RCNN보다 20배 이상 빠르지만, training이 여전히 여러 단계이고 SPPNet 이전의 모든 계층을 무시한 채 fc layer만 fine-tuning한다는 단점이 있다.
Fast RCNN - 2015년 RCNN과 SPPNet을 개선한 Fast RCNN이 제안되었는데, 이 모델은 한 network에서 detector와 bounding box regressor를 동시에 training할 수 있게 되었다.이는 R-CNN보다 추론 속도가 200배 이상 빠르면서 mAP를 58.5%에서 70.0%로 늘렸다. 이는 R-CNN과 SPPNet의 장점을 성공적으로 통합한 것이지만, 검출 속도는 여전히 proposal detection에 제한된다는 단점이 있다.
Faster R-CNN - 2015년 제안된 Faster RCNN은 최초로 near-realtime 딥러닝 Detector이다. 이 모델의 주요 contribution은 RPN의 제안으로 거의 연산이 들지 않는 region proposal이 가능하게 했다는 것이다. RCNN부터 Faster R-CNN까지 이르면서 Object detection 모델은 개별 모듈들이 end-to-end로 통합되었다. Faster R-CNN은 Fast R-CNN의 속도 병목 현상을 일부 해결했지만 detect 단계에서는 여전히 중복이 있다.
FPN - FPN은 2017년 제안되었다. 이전의 대부분의 딥러닝 기반 모델들은 network의 top layer에서만 detect를 했는데, 이는 CNN의 더 깊은 층의 인식에는 유용하지만 localizing에는 도움이 되지 않는다. 이를 위해 FPN이 개발되었고 모든 스케일에서 high-level semantics를 구축하기 위해 lateral connection과 같은 top-down 방식의 구조가 개발되었다. Faster R-CNN에 FPN을 적용해 단일 모델 SOTA를 달성한다. FPN은 많은 최신 detecotr들의 기본 구성 요소가 되었다.
2) CNN based One-stage Detectors
대부분의 Two-stage Detectors는 coarse-to-fine(거친수준 -> 미세한 수준)의 처리 패러다임을 따른다. 그것들은 다른 부가장치 없이 높은 정밀도를 쉽게 얻을 수 있지만 속도와 복잡성 때문에 engineering에는 거의 사용되지 않는다. 반대로 One-stage Detector는 한 번의 추론으로 모든 물체를 검색할 수 있어 real-time과 easy-deployed features을 가진 모바일 기기에서 인기가 있지만, 밀도가 높고 작은 물체를 탐지할 때의 성능에 문제가 있다.
YOLO - YOLO는 2015년 제안된 아주 빠른 속도의 딥러닝 기반의 최초의 One-stage Detector이다. YOLO는 단일 신경망을 전체 이미지에 적용한다. 이러한 network는 이미지를 영역으로 나누고 각 영역에 대한 bbox와 class score를 동시에 예측한다. 탐지 속도가 크게 향상되었지만 일부 작은 물체의 경우 localization 성능이 떨어진다. 최근 YOLOv4 팀이 YOLOv7을 제안했는데, 동적인 label assignment와 무델 구조 재파라미터화를 거쳐 기존의 모델들보다 속도와 정확도가 뛰어나다.
SSD - SSD는 multi-reference와 multi-resolution detection techniques으로 특히 작은 물체에 대한 One-stage Detector의 정확도를 크게 향상시켰다. SSD는 속도와 정확도에서 큰 장점이 있고, 이전 모델들과의 주요한 차이점은 network에서 다른 층에서 다른 규모의 객체를 인식한다는 것이다.
RetinaNet - 빠른 속도와 낮은 복잡도에 도 불구하고 One-stage detector는 Two-stage detector의 정확도를 뒤따라왔다. 그 이유를 조사하여 제안된 것이 RetinaNet이다. 저자들은 극심한 foreground-background clasee의 불균형이 주요 원인이라는 것을 발견했고, 이를 위해 detector가 학습 중에 단단하고 잘못 분류된 예제에 더 초점을 맞출 수 있도록 표준 교차 엔트로피 손실을 재구성하여 모델에 "focal loss"라는 손실함수를 도입했다. 이를 통해 One-stage detector는 매우 높은 속도를 유지하면서 Two-stage detector와 비슷한 정확도를 달성할 수 있었다.
DETR - 최근 Transformer가 딥러닝 전반에 주요한 영향을 끼쳤다. Transformer는 CNN의 한계를 극복하고 global-scale receptive field를 덩기 위해 기존 conv 연산을 제외한다, 2020년에 DETR이 제안되었는데, 여기서 Object detection을 set prediction problem으로 보고 end-to-end network를 제안한다. 이 후 모델은 anchor box나 anchor point를 사용하지 않고 객체를 탐지할 수 있는 새로운 시대에 접어들게 되었다. 이후 DETR은 긴 학습 수렴 시간과 작은 객체 탐지에 대한 성능을 보완하기 위해 변형 가능한 DETR이 제안된다.
B. Object Detection Datasets and Metrics
1) Datasets
더 크면서 편향이 적은 Dataset을 만드는 것은 detection algorithms을 발전시키는데 필수이다. 잘 알려진 detection datasets는 지난 10여년간 릴리즈되어왔다.

Pascal VOC - Pascal Visual Object Classes는 초기 CV 커뮤니티의 중요한 대회였다. 두 개 버전의 데이터셋인 VOC07과 VOC12 중 전자는 5k의 tr image와 12k의 annotated objects가 있고 후자는 11k의 tr image와 27k의 annotated objects가 있다. 또한 일상에서 흔히 마주칠 수 있는 20개의 객체들이 포함되어있다.
ILSVRC - ImageNet Large Scale Visual Recognition Challenge의 줄임말로, 일반적인 object detection에 첨단 기술을 도입했다. ILSVRC는 200개의 class를 갖고 이미지와 인스턴스 수는 VOC보다 2배 큰 규모이다.
MS-COCO - MS-COCO는 오늘날 사용가능한 가장 도전적인 데이터셋 중 하나이다. 이것을 기반으로 매년 열리는 대회는 2015년부터 개최되고 있고, 객체의 카테고리 수는 ILSVRC보다 적지만 객체 인스턴스 수는 더 많다. VOC 및 ILSVRC와 비교해 MS-COCO는 bounding box 외에 각 객체에 instance segmentation을 추가 label로 지정해 정확한 Localization을 지원한다. 또한 이 데이서셋은 더 많은 작은 객체와 더 밀집한 객체들이 포함되어 있다.
2) Metrics
detection의 정확도를 어떻게 평가할 수 있을까? 이 질문의 대답은 매 번 바뀔 것이다. 초기의 연구에서는 넓게 적용되는 evaluation metrics가 없었다. 예를 들어, 초기에는 FPPW(miss rate vs false positives per window)라는 지표가 많이 사용되었다. 하지만 per-window 측정은 결함이 있을 수 있으며 전체 이미지 성능을 예측하지 못한다. 2009년엔 FFPI(false positives per image)가 도입되었다.
최근 가장 널리 사용되는 지표는 AP(Average Precision)이다. AP는 다양한 recall의 average precision이며 이것은 일반적으로 범주별로 계산된다. 모든 카테고리에 걸쳐 평균을 낸 평균 mAP는 일반적으로 최종 성능지표로 사용된다. 객체 위치의 정확도를 측정하기 위해서는 predicted box와 ground truth의 IoU를 사용해 미리 정의된 임계값보다 큰지 여부에 따라 탐지된 것인지 확인한다. 0.5임계값의 IoU의 mAP가 사실상 Obeject detection의 지표가 되었다.
2014년 이후 MS COCO dataset에서 연구자들은 객체의 위치의 정확도에 더 초점을 두면서 fixed IoU 대신 MS-COCO AP를 쓰기 시작했는데 이것은 0.5와 0.95 사이의 여러 임계값에 대한 IoU의 평균을 낸다.
C. Technical Evolution in Object Detection
1) Technical Evolution of Multi-Scale Detection
이것은 다른 사이즈 또는 다른 비율의 객체를 탐지하는 것은 이 분야의 주요한 technical challenge이다.
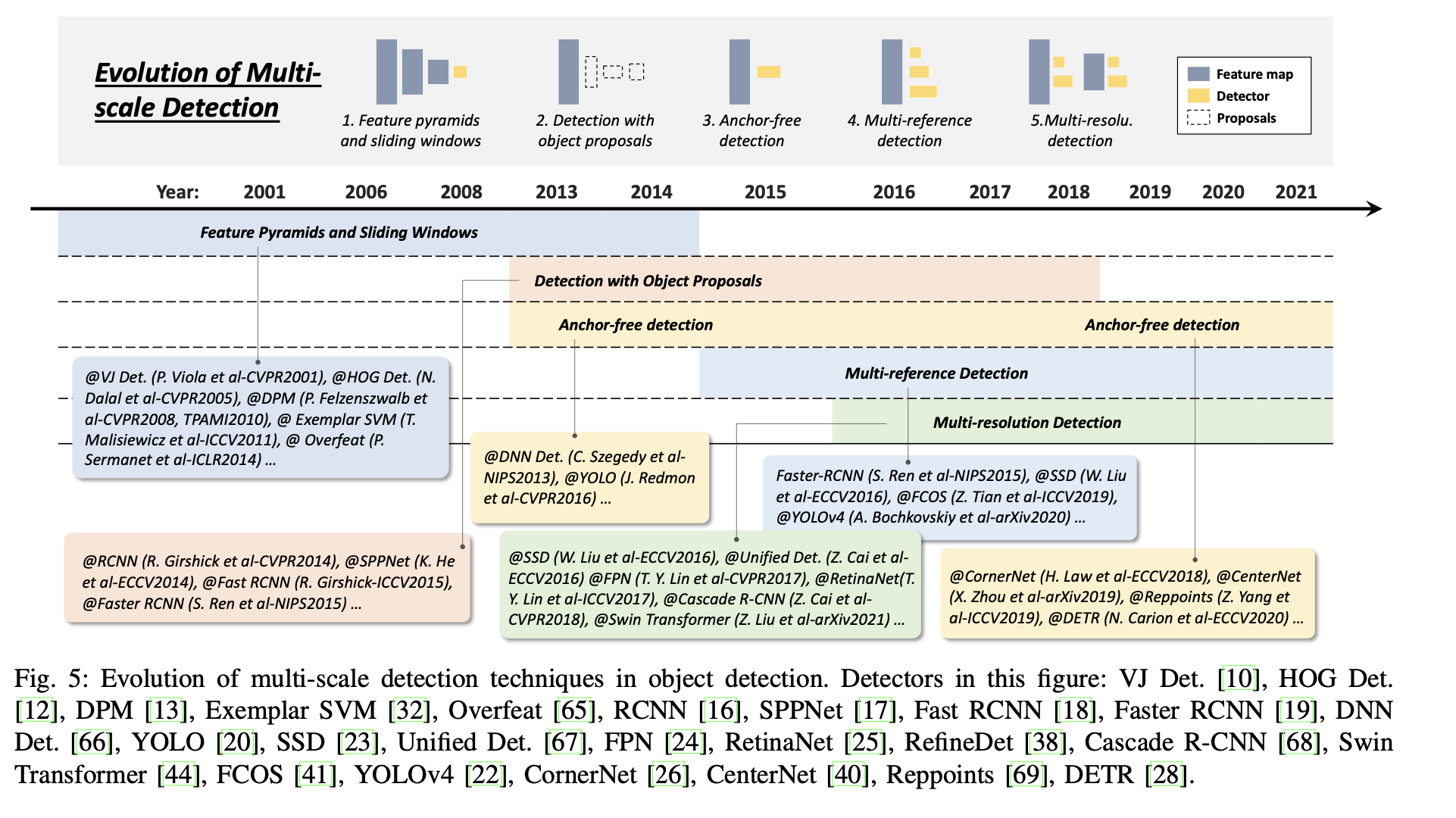
Detection with object proposals - Object proposals은 모든 객체를 포함할 가능성이 있는 클래스에 구애받지 않는 reference box들을 의미한다. 이것을 통해 detect는 이미지 전반에 걸친 sliding window serach를 방지할 수 있게 한다. 2014년 이후 Visual recognition에서 CNN이 인기를 끌면서 학습 기반의 하향식 접근 방식이 이 문제에서 더 많은 이점을 보이기 시작했다. 현재는 One-stage detector의 부상 이 후 점차 보이지 않게 되었다.
Deep regression and anchor-free detection - GPU의 연산량이 증가함에 따라 Multi-scale detection은 점점 더 간단해졌다. Multi-scale 문제를 해결하기 위해 deep regression을 사용하는 아이디어는 간단해진다. 즉, Deep learning features에 기반해 bbox의 좌표를 직접 예측하는 것이다. 2018년 이후 연구자들은 keypoint detection의 관점에서 두 가지 아이디어를 따른다. 하나는 Keypoint를 감지한 후 객체별 그룹화를 수행하는 그룹기반 방식이고, 하나는 객체를 하나 또는 다수 keypoint로 간주한 다음 객체의 속성(크기, 비율)을 point의 reference로 두는 것이다.
Multi-reference/-resolution detection - Multi-reference detection은 multi-reference detection을 위한 가장 많이 쓰여지는 방법이다. multi-reference detection의 주요 아이디어는 reference의 세트(box 및 point를 포함한 anchors)을 정의한 다음 이 기준들을 기반으로 box를 예측하는 것이다. 또 다른 인기 있는 기술은 Multi-resolution, 즉 network의 서로 다른 계층에서 서로 다른 scale의 객체를 검출하는 것이다. 이 두 기술은 SOTA 모델들에서 기본 구성요소가 되었다.
2) Technical Evolution of Context Priming
visual objects는 일반적으로 주변 환경과 전형적인 context에 포함된다. 우리의 뇌는 시각적 인식과 인지를 용이하게 하기 위해 대상과 환경 사이의 연관성을 이용한다. Context priming은 detection을 향상시키기 위해 오랫동안 사용되어왔다.
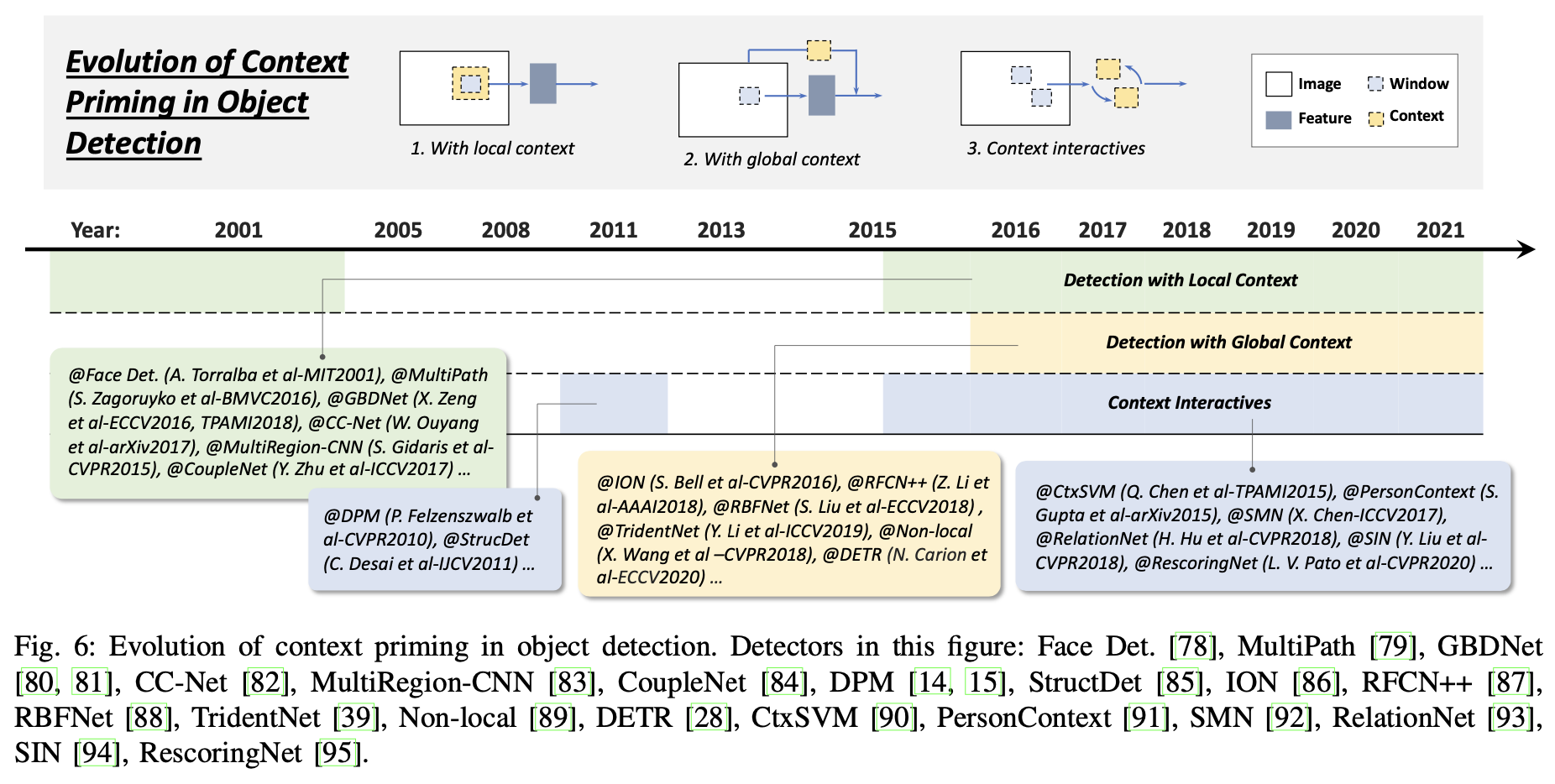
Detection with local context - Local context는 객체를 둘러싸고 있는 영역의 시각적 정보를 의미한다. Local context가 객체 탐지를 향상시킨다는 것은 오랫동안 인정되어 왔다.
Detection with global context - global context는 객체 탐지를 위한 추가적인 소스로 scene구성을 활용한다. 최근 detector들의 global context를 통합하는 방법은 두 가지가 있다. 첫째는 deep convolutional network, dilated convolution, deformable convolution, 그리고 Pooling을 이용해 큰 receptive field(>입력 이미지)를 받는 것이다. 그러나 현재 연구자들은 전체 이미지 receptive field를 달성하기 위해 attention기반의 메커니즘을 적용할 수 있는 가능성을 탐구했으며 큰 성공을 거두었다. 두 번쨰 방법은 global context를 일종의 sequential information으로 생각하고 rnn으로 학습하는 것이다.
Context interactive - context의 상호 작용는 시각적인 요소 간에 전달되는 제약과 종속성의 의미한다. 최근 일부 연구에서는 이것을 고려해 detector들을 개선할 수 있다고 했다. 일부 최근 개선 사항은 두 종류로 첫째는 개별 객체 간의 관계를 탐색하는 것이고 둘째는 객체와 scene 간의 종속성을 탐색하는 것이다.
3) Technical Evolution of Hard Negative Mining
detector들의 training은 본질적으로 불균형적인 학습이다. sliding window 기반의 detector의 경우 배경과 객체 간의 불균형이 107:1만큼도 극심하다. 이러한 경우, vast number of easy negatives 학습 과정을 압도해 모든 배경을 사용하는 것이 좋지 않을 것이다. HNM(Hard Negative Mining)은 이문제를 극복하는 것을 목표로 한다.
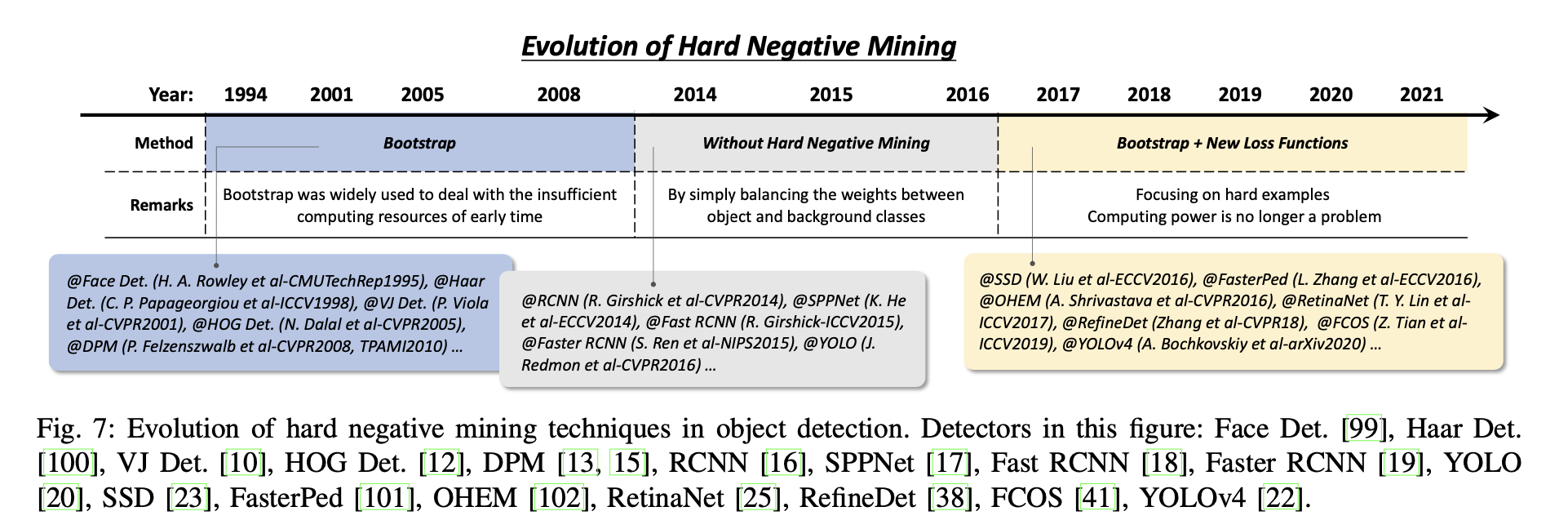
HNM in deep learning based detectors - 딥러닝 시대의 연산 능력 증가로 2014~2016년 동안 Object detection에서 bootstrap은 거의 제외되었고, 학습 중 불균형 문제를 완화하기 위해 Faster R-CNN과 YOLO와 같은 탐지기는 positive/negative windows 사이의 가중치를 단순히 맞추었다. 그러나 연구자들은 나중에 이것이 불균형 문제를 완전히 해결할 수 없다는 것을 알게되었고, 이를 위해 bootstrap이 object detection에 다시 도입되었다. 개선 사항은 표준 교차 엔트로피 손실을 재구성하여 새로운 손실 함수를 설계하여 잘못 분류된 예제에 더 초점을 맞추는 것이다.
4) Technical Evolution of Loss Function
Object detection에서 일반적인 Classficiation과 localization loss는 아래 수식과 같다. 여기서 p는 category probabilties, t는 location, η는 IoU 임계값을 의미한다. 만약 anchor box/point가 배경으로 판정되면 locatization loss가 final loss에 반영되지 않는다.
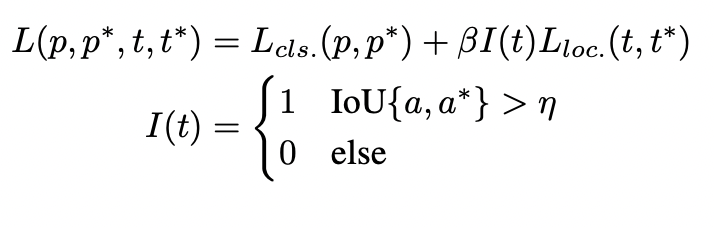
Classification loss - 이것은 주로 MSE/L2를 사용하는 YOLOv1~2 같은 이전 모델들에서 충분히 연구되지 않은 class 분류에서의 오차의 발산을 평가하는데 사용된다. 나중에는 Cross-Entropy가 주로 사용된다. L2 loss는 유클리드 공간의 개념인 반면 CE는 분포의 차이를 측정할 수 있다. 분류의 예측값은 확률이므로 CE loss는 잘못된 분류 비용이 더 크고 더 낮은 기울기 소실 문제로 L2 loss보다 선호된다. 분류 효율성을 향상시키기 위해 Label Smooth는 모델 일반화 능력을 향상시키고 노이즈 라벨에 대한 overconfidence 문제를 해결하기 위해 제안되었으며, Focal loss는 category 불균형 및 분류 난이도 차이 문제를 해결하기 위해 설계되었다.
Localization loss - 이는 위치 및 크기 편차를 최적화하기 위해 사용된다. L2 loss는 초기 연구에서 널리 사용되었지만 이상치의 영향을 많이 받고 기울기 폭발 문제가 있다. 연구자들은 L1과 L2의 이점을 합쳐 다음과 같은 Smooth L1 loss를 제안한다. 여기서 x는 예측과 실제의 차이를 의미한다.
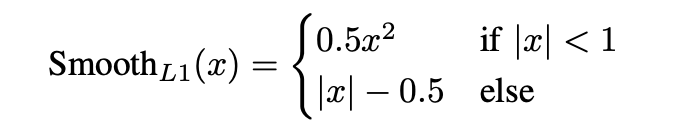
오차를 계산할 때, 위 수식은 bbox를 표현하는 네 개의 값을 독립적인 변수들로 다룬다. 하지만 그들 사이의 상관관계는 있다. 또한 IoU를 활용해 평가 시 bbox가 ground truth에 해당하는지 여부를 판단한다.
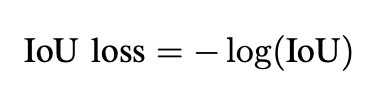
5) Technical Evolution of Non-Maximum Suppression
이웃한 window들은 대개 비슷한 detection score를 가지므로 non-maximum suppression은 replicated bounding boxes를 제거하고 최종 결과를 얻기 위한 후처리 단계로 사용된다. Object detection 초기에는 항상 NMS가 통합되지 않았다. 그 당시에는 시스템의 원하는 출력이 완전하지 않았기 때문이다.
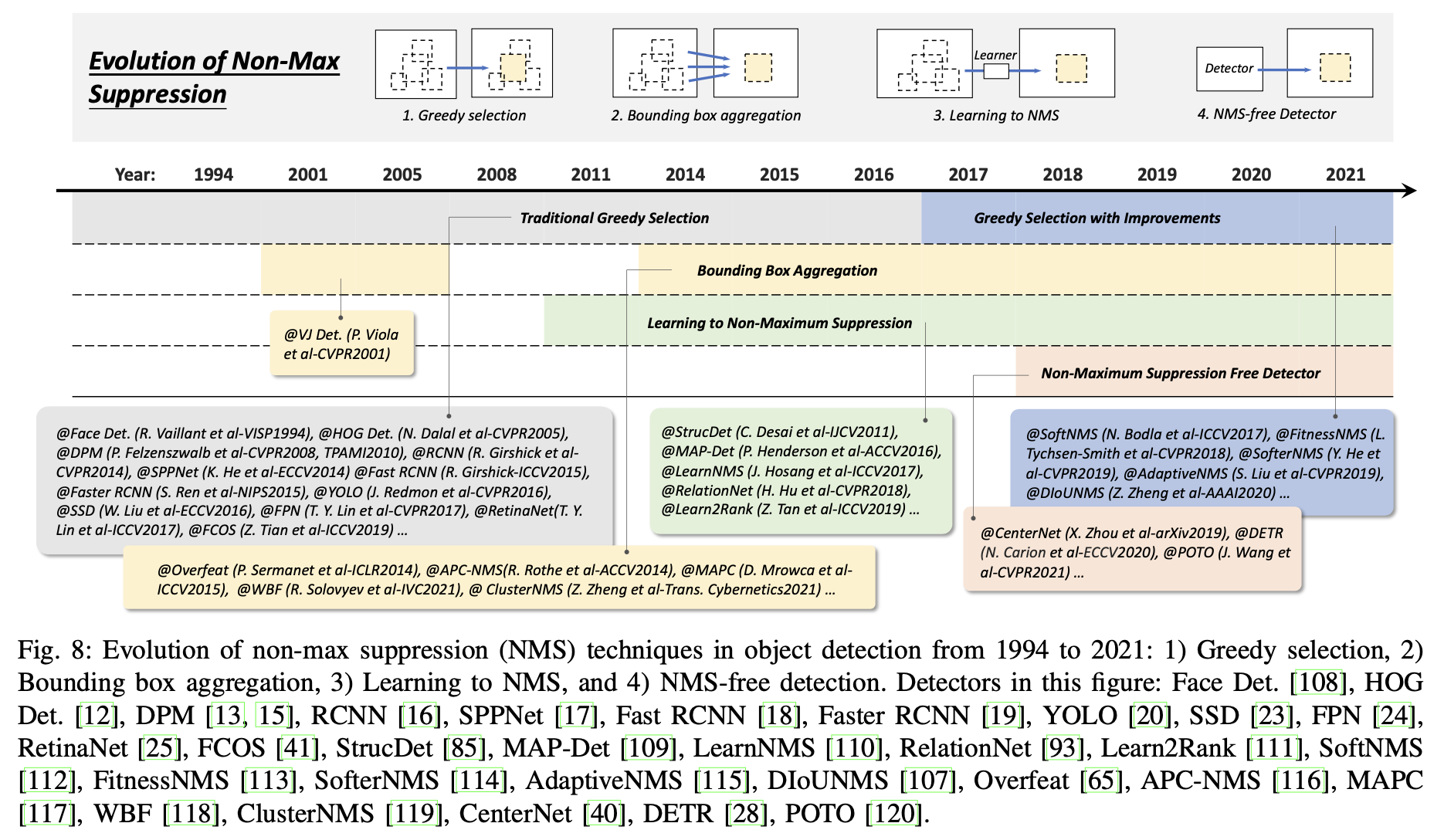
Bounding box aggregation - 이것은 여러 개의 중첩된 BB를 하나의 최종값으로 결합하거나 클러스터링하는 아이디어를 가진 NMS에 대한 또 다른 기술이다. 이 방식의 장점은 객체 관계와 spatial layout을 고려한다는 것이다.
Learning based NMS - 최근 많은 관심을 받는 NMS 개선 사항은 학습 기반 NMS이다. 주요 아이디어는 NMS를 필터로 생각해 모든 raw detection의 점수를 다시 매기고 network의 일부로써 end-to-end로 학습시키거나 NMS의 동작을 따라하도록 net을 훈련시키는 것이다. 이러한 방식은 기존 수작업 NMS 방법에 비해 폐색되거나 dense한 object 탐지에 더 좋은 결과를 보여주었다.
NMS-free detector - NMS 없이 fully end-to-end 모델을 만들기 위해 연구자들은 일대일 라벨 할당을 위한 방법을 개발했다. 이러한 방법들은 종종 free-NMS를 달성하기 위한 학습을 위해 highest-quality의 box를 사용해야한다. NMS가 없는 Detector는 인간의 시각 인식 시스템과 더 유사하며 이 분야가 미래로 나아갈 수 있는 방법이다.
3. Speed-Up Of Detection
Detector의 가속은 계속 연구되어 왔다. 객체 탐지에서 speed-up 기술은 세 가지 레벨로 나뉜다: “detection pipeline”, “detector backbone”, 그리고 “numerical computation”의 가속화.
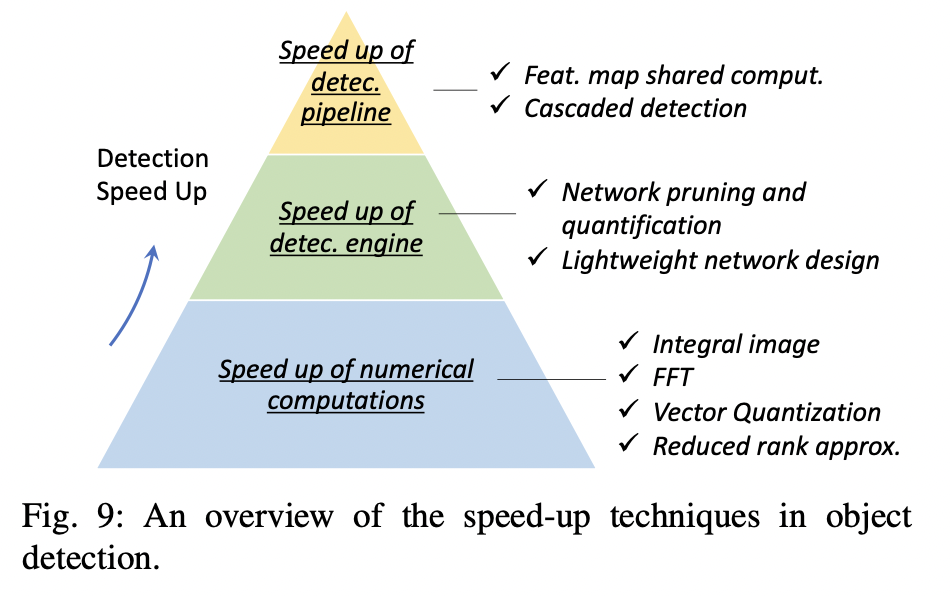
A. Feature map Sharped Computation
- detector의 다양한 computational stages 중 feature extraction은 일반적으로 많은 연산량을 차지한다. 이를 줄이기 위해 주로 사용된 아이디어는 전체 이미지에 대한 연산을 한 번만 계산하는 것이고 이는 10배 심지어 100배까지 가속화를 시켰다.
B. Cascaded Detection
Cascaded detection은 자주 사용되는 기술이다. 이것은 대부분의 단순한 배경 window을 간단한 계산을 통해 필터링한 다음 복잡한 계산으로 어려운 window를 처리하는 coarse to fine deteciton philosophy가 필요하다. 최근 몇 년 동안 cascaded detectiond은 얼굴 탐지, 보행자 감지와 같은 "큰 장면의 작은 물체"탐지 task들에 적용되었다.
C. Network Pruning and Quantification
"Network Pruning"과 "Network Quantification"은 CNN 모델의 속도를 높이기 위해 일반적으로 사용되는 두 가지 방법이다. 전자는 구조 또는 가중치를 가지치기하는 것이고 후자는 코드의 길이를 줄이는 것을 의미한다. 최근의 Pruning은 일반적으로 반복적인 학습 및 가지치기, 즉 각 학습 단계 후에 중요하지 않은 가중치의 작은 그룹만 제거하고 해당 작업을 반복한다. Network Quantification의 최근 연구들은 주로 Network binarization에 초점을 맞추어, Network의 활성화 또는 가중치를 이진 변수로 정량화하여 부동 소수점 연산을 논리 연산으로 변환하여 network를 압축하는 것을 목표로 한다
D. Lightweight Network Design
- CNN 기반의 detector를 가속화하는 마지막 방법은 경량화 네트워크를 만드는 것이다. "더 적은 channel과 더 많은 layer"와 같은 일반적인 설계 외에도 다른 방법이 있다.
1) Factorizing Convolution - 이것은 경량화 CNN 모델을 구축하는 가장 간단한 방법이다. Factorizing에는 두 가지 방식이 있다. 첫 번째는 그림 10(b)와 같이 큰 conv filter를 작은 것들의 집합으로 만드는 것이다. 여기서 동일한 receptive field를 사용하게 되지만 후자의 필터가 더 효율적이다. 두 번째 방식은 그림(c)와 같이 채널 차원에서 factorizing을 진행하는 것이다.
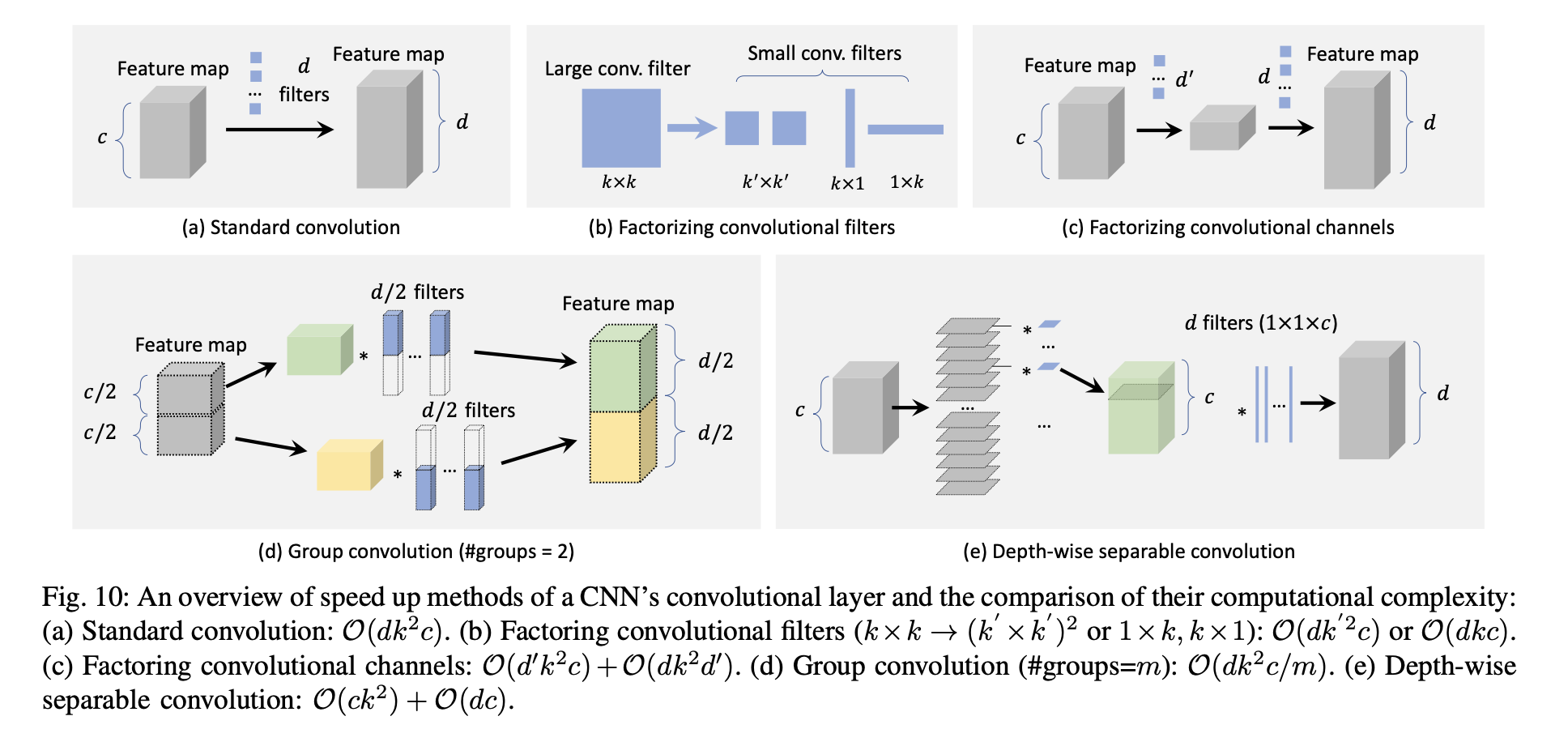
2) Group convolution - 이것은 그림 10(d)와 같이 feature channel을 다른 그룹으로 분할하여 convolution 계층의 파라미터 수를 줄인 다음 각 그룹에서 독립적인 conv 연산을 하는 것을 목표로 하는데, 만약 feature를 m개의 그룹으로 균등하게 분할하면 이론적으로 연산량이 1/m이 줄어든다.
3) Depth-wise Separble Convolution - 그림10(e)와 같이 깊이 별로 분리 가능한 convolutiond은 그룹의 수가 채널의 수와 동일하게 설정될 때 Group convolution의 특수한 경우로 볼 수 있다. 일반적으로 최종 출력이 원하는 개수의 채널을 갖도록 차원 변환을 수행하기 위해 다수의 1x1 conv 연산이 적용된다. 깊이 별 분리가 가능한 conv 연산을 사용함으로써 계산을 O(dk2c)에서 O(ck2)+O(dc)로 줄일 수 있다.
4) Bottle-neck Design - Bottleneck design은 너무 유명해서 생략
5) Detection with NAS - 딥러닝 기반의 detector는 점점 더 정교해지고 있으며, 수작업을 통한 모델 구조와 학습 파라미터에 크게 의존하고 있다. 탐지 모델을 설계할 때 NAS는 network backbone 및 anchor box 설계에 인간 개입의 필요성을 줄일 수 있다.
E. Numerical Acceleration
Numerical Acceleration는은 구현의 바닥에서부터 detector를 가속시키는 것을 목표로 한다.
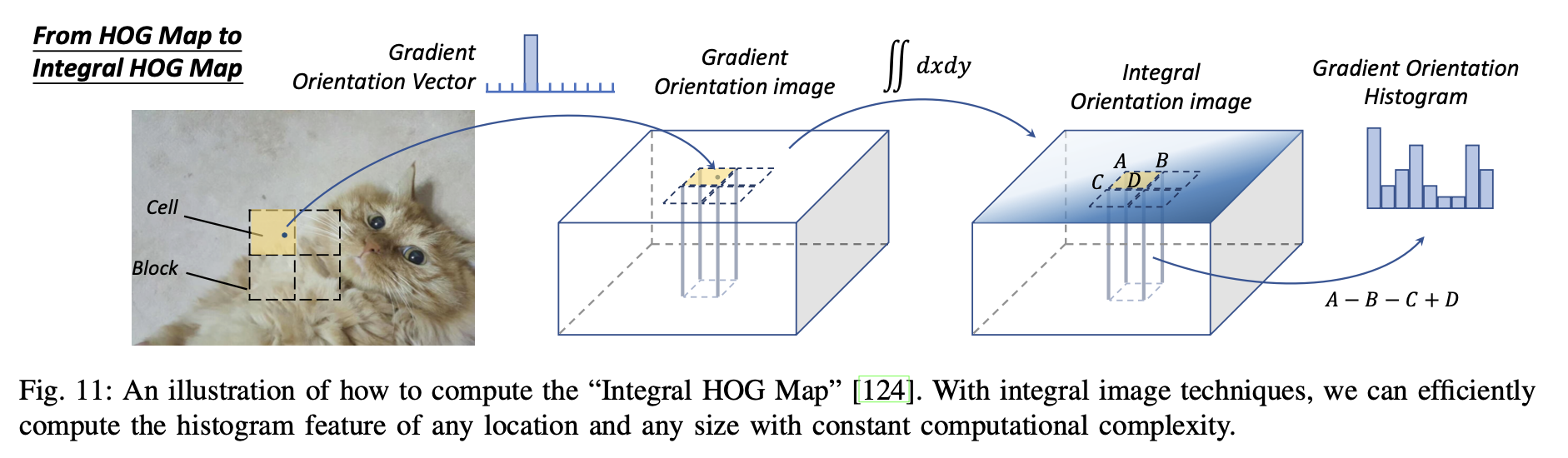
1) Speed Up with Integral Image - 통합된 이미지? 는 이미지 처리에서 중요한 방법이다. 이미지 하위 영역에 대한 합산을 빠르게 계산하는데 도움이 되고, 이것의 본질은 신호 처리에서 적분과 미분 분리성이다.
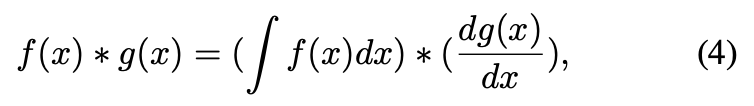
dg(x)/dx가 sparse signal이고, convolution은 우항의 식을 통해 계산을 가속화 시킬 수 있다. 통합 이미지는 객체 탐지에서 일반적인 features를 가속화하는데 쓰일 수 있다.
2) Speed Up in Frequency Domain - Convolution은 객체 탐지에서 중요한 연산이다. linear detector의 detect는 convolution으로 구현될 수 있는 feature map과 detectors weight 사이의 window-wise inner product로 볼 수 있기 때문이다(1X1 conv가 linear 연산인 것을 말하는 듯?). 푸리에 변환은 Convolution 속도를 높이는 실용적인 방법이며, 여기서 이론적 기초는 신호 처리의 convolution theorem이다.
3) Vector Quantization - 벡터 양자화는 신호 처리의 고전적인 양자화 방법으로, 프로토타입 벡터의 작은 집합에 의한 대규모 데이터 그룹의 분포 근사화를 목표로 한다. 이는 객체 탐지에서 데이터 압축 및 내부 연산 가속화에 사용될 수 있다.
4. RECENT ADVANCES IN OBJECT DETECTION
지난 20년 동안 지속적인 신기술의 등장은 객체 탐지에 상당한 영향을 미친 반면 그 근본적인 원리는 변하지 않았다. 위 목차들에서는 지난 기술 발전을 소개했고, 여기서는 이해를 돕기 위해 최근의 알고리즘들에 더 집중할 것이다.
A. Beyond Sliding Window Detection
이미지의 객체는 gt bbox의 왼쪽 상단 및 오른쪽 하단 코너에 의해 고유하게 결정될 수 있기 때문에 탐지 task는 pair-wise key points localization 문제와 동등하게 구성될 수 있다. 이 아이디어의 최근 구현 중 하나는 코너에 대한 heatmap을 예측하는 것이다. 다른 방법으로는 이 아이디어를 따르며 더 많은 keypoint를 활용해 더 좋은 성능을 얻는 것이다. 또 다른 방법은 객체를 point/point로 보고 그룹화하지 않고 객체의 속성(h, w 등)을 직접 예측한다. 이 접근법의 장점은 semantic segmentation에 적용할 수 있고 multi-scale anchor box를 설계할 필요가 없다는 것이다. 또한 객체 탐지를 set prediction으로 간주해 DETR은 reference-based framework에서 완전히 벗어난다.
B. Robust Detection of Rotation and Scale Changes
최근 rotation과 scale 변화를 감지하기 위한 연구가 이어졌다.
1) Rotation Robust Detection - 객체의 회전은 face detection, text detection, and remote sensing object detection에서 흔히 볼 수 있다. 이 문제의 간단한 해결책은 어떤 방향의 객체가 augmented data distribution의해 잘 커버될 수 있도록 데이터 증강을 하거나, 각 방향에 대해 독립적인 detector를 별도로 학습시키는 것이다. rotation invariant loss function을 설계하는 것은 최근 인기 있는 해결책으로, 회전된 객체의 특징이 변하지 않도록 detection loss에 대한 제약이 추가된다. 또 다른 최근 해결책은 객체 후보에 대한 기하학적 변환을 학습하는 것이다. Two-stage detector에서 RoI pooling은 임의의 위치와 크기를 가진 객체 후보에 대한 fixed-length feature representation를 추출하는 것을 목표로 한다. feature pooling은 일반적으로 데카르트 좌표로 수행되기 때문에 회전 변환에 의해 변하지 않는 것은 아니다. 최근 개선된 점은 polar coordinates에서 RoI pooling을 수행해 feature가 회전 변화에 robust할 수 있게 만드는 것이다.
2) Scale Robust Detection - 최근 연구는 학습 및 탐지 단계 모두에서 scale에 robust하게 이루어졌다.
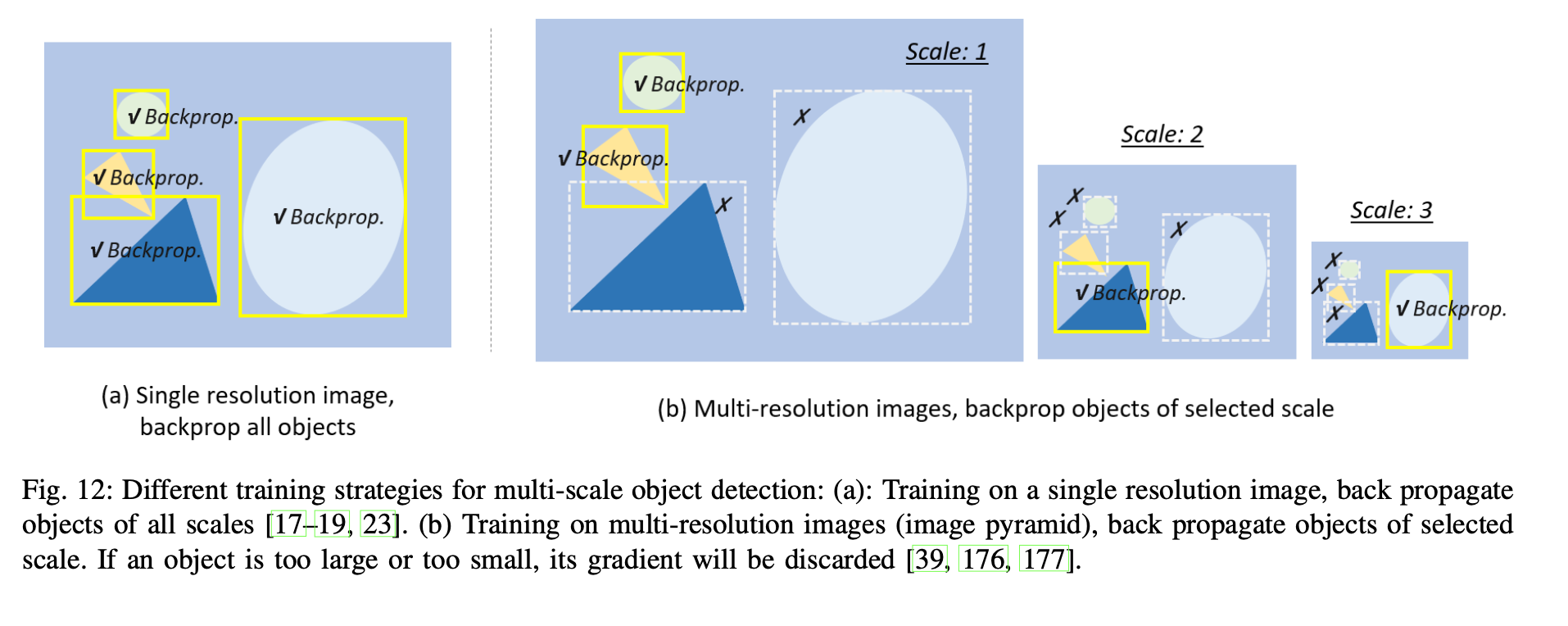
2-1) Scale Adaptive training - 현대의 detector들은 일반적으로 입력 이미지의 scale을 고정된 크기로 조정하고 모든 scale에서 객체에 대한 손실을 역전파한다. 이 때의 단점은 "scael imbalance"이다. 탐지 중에 image pyramid를 구성하면 완화시킬 수 있지만 근본적인 해결책은 아니다. 최근 개선된 사항은 image pyramid에 대한 Scale Normalization으로, 그림12와 같이 학습 및 탐지 단계 모두에서 Image pyramid를 구성하고 일부 선택된 scale의 손실만 역전파한다. 일부 연구자들은 이미지를 잘라내고 하위 영역의 set로 rescaling하여 이미지를 생성하는 효율적은 학습 전략을 제안했는데, 이는 Large batch training에서 이점이 있다.
2-2) Scale adaptive detection - CNN 기반 detector에서 일반적으로 anchor의 크기와 종횡비가 세밀하게 설계된다. 이렇게 하는 경우의 단점은 모델 구성이 예상치 못한 scale 변화에 적응할 수 없다는 것이다. 작은 물체의 감지를 향상시키기 위해 최근 일부 detector들은 작은 물체를 "더 큰 것"으로 adaptive하게 확대하는 "adaptive zoom-in" 기술이 제안된다. 또 다른 최근 개선 사항은 이미지에서 물체의 scale 분포를 예측한 후 그에 따라 이미지를 adaptive하게 scaling하는 것이다.
C. Detection with Better Backbones
D. Improvements of Localization
Localization 정확도를 향상시키기 위해 최근엔 두 가지 방식이 사용되고 있다.
1) Bounding Box Refinement - 가장 직관적인 방법으로, 탐지 결과의 후처리로 볼 수 있다. 최근 제안 방식은 탐지 결과를 반복적으로 bbox regressor에 입력해 예측이 올바른 위치와 크기로 수렴할 때까지 반복하는 것이다. 하지만 일부 연구자들은 이 방식이 localization 정확도를 보장하지 않는다고 언급했다.
2) New Loss Functions for Accurate Localization - 대부분의 최신 detector들은 객체 Localization을 좌표에 대한 회귀 문제로 간주한다. 그러나 이 방식의 단점은 분명하다. 첫째, 회귀 손실은 매우 큰 aspect ratio를 가진 일부 객체에 대해 localization의 최종 평가와 일치하지 않는다. 둘째 전통적인 bbox regressor는 localization의 신뢰도를 제공하지 않는다. 이러한 문제들은 새로운 loss function의 설계로 보완할 수 있다. 가장 직관적인 법은 IoU를 사용하는 것이다. 또한 일부 연구자들은 확률적 추론 프레임워크 하에서 localization을 개선하려고 시도했다. 이 방식은 이전의 직접적인 bbox를 에측하는 방법과 달리 bbox 위치의 확률 분포를 예측한다.
E. Learning with Segmentation Loss
Object detection과 semantic segmentatoin은 CV에서 기본적인 task라고 할 수 있다. 최근 연구들은 semantic segmentation loss를 활용해 객체 탐지를 개선할 수 있다고 제안하고 있다.
이의 가장 간단한 방법은 segmnetaion network를 fixed-feature extracter로 간주하고 이를 detector에 auxiliary features로 결합시키는 것이다. 이 방법의 장점은 세그멘테이션 브랜치가 추론 단계에서 제거되며 검출 속도에 영향을 미치지 않는다는 것입니다. 그러나 단점은 훈련에는 픽셀 수준의 이미지 주석이 필요하다는 것입니다.
F. Adversarial Training
2014년 GAN이 나오면서 큰 주목을 받았는데 최근에 객체 탐지를 위해 적용되었다. 특히 작고 가려진 객체들의 탐지를 개선하기 위해 적용되고 있다.
작은 객체 검출에서 GAN은 작은 객체와 큰 객체 간의 representation 간격을 줄이는 방식으로 작은 객체의 특징을 강화하는데 사용될 수 있다. 이 방법은 작은 객체의 feature를 뚜렷하게 만들어 구별 가능하게 함을 목표로 한다.
가려진 객체 탐지를 향상시키기 위해 최근에 제안된 아이디어 중 하나는 적대적 훈련을 사용해 occlusion masks를 생성하는 것이다. 픽셀 공간에서 예제를 생성하는 대신 적대적인 네트워크는 직접 feature를 수정해 occlusion을 모방한다. 이는 detector가 가려진 상황에서 더 잘 처리할 수 있는 견고한 representation을 학습하게 하여 탐지 성능을 향상시킨다.
G. Weakly Supervised Object Detection
딥러닝 기반의 detector를 학습시키는 것은 많은 양의 labeled data가 필요하다. Weakly Supervised Object Detection는 bbox 대신 이미지 레벨의 label만 사용해 detector를 학습시켜 labeld data에 대한 의존성을 줄이고자 한다.
H. Detection with Domain Adaptation
대부분의 detector에서 학습 과정은 독립적이고 동일하게 분포된(i.i.d) 데이터라는 가정 하에서의 우도 추정 프로세스로 볼 수 있다. 특히 일부 실제 응용 분야에서의 non-i.i.d 데이터에 대한 객체 탐지는 여전히 어려운 과제이다. 더 많은 데이터 수집이나 적절한 증강을 적용하는 것 외에도 도메인 적응은 도메인 간의 간격을 줄일 수 있다.
5. CONCLUSION AND FUTURE DIRECTIONS
앞으로의 유망한 연구로 다음과 같은 분야를 언급할 수 있다.
1. Lightweight object detection - 이것은 저전력의 모바일 디바이스에서 실행할 수 있도록 속도를 향상시키는 것을 목표로 한다. 모바일 증강 현실, 자율주행, 스마트 시티, 스마트 카메라, 얼굴 인식 등과 같은 주요한 응용 분야가 있다. 최근 몇 년간 많은 노력이 있었지만, 특히 일부 작은 객체를 감지하거나 다중 정보를 활용해 감지하는 경우 기계와 인간의 속도 차이가 여전히 크다.
2. End-to-End object detection - 일부 방법은 이미지에서 box로의 완전한 end-to-end 방식으로 객체를 탐지하지만, 대다수는 여전히 NMS 연산이 별도로 사용한다. 향후 이 주제에 대한 연구는 높은 정확도와 효율성을 모두 유지하는 End-to-end 파이프라인을 설계하는데 중점을 둘 수 있다.
3. small object detection - 큰 이미지에서 작은 객체를 탐지하는 것은 오랫동안 어려운 과제였다. 이 연구 방향의 잠재적인 응용 분야에서는 군중 속 인구나 야외 동물의 수를 세는 작업 및 위성 이미지에서 군사적 대상을 감지하는 것을 예로 들 수 있다.
4. 3D Objedt detection - 최근 2d 객체 탐지의 발전에도 불구하고 자율 주행과 같은 분야는 3D 세계에서의 더 많은 주목을 받으며 다중 소스 및 다중 뷰 데이터의 활용이 더 강조될 것이다.
5. Detection in videos - 고화질 영상에서 real-time 객체 탐지 및 추적은 영상 감시와 자율주행에 매우 중요하다. 전통적인 detector는 이미지별 감지를 위해 개발되었으며 영상 프레임 간의 상관관계를 무시한다. 연산량의 제약 하에서 sptial&temporal 상관관계를 탐색해 감지를 개선하는 것은 중요한 연구 방향이다.
6. Cross-modality detection - 여러 소스/modality 데이터를 사용한 객체 탐지는 인간의 지각과 유사한 정확한 검출 시스템을 위해 매우 중요하다.
7. Towards open-world detection - Out-of-domain general- ization, zero-shot detection, 그리고 incremental detection은 떠오르는 주제이다. 대부분의 연구들은 재안정성을 감소시키거나 보조 정보를 활용하는 방법을 고안했다. 인간은 환경에서 알려지지 않은 범주의 객체를 발견하는 본능이 있는데, 해당 label이 주어지면 새로운 지식을 배우고 패턴을 유지할 수 있다. 하지만 현재 객체 탐지 알고리즘은 알려지지 않은 범주의 객체를 감지하는 능력을 이해하기 어렵다. open world에서 객체 탐지는 명시적으로 주어지지 않거나 부분적으로 주어진 경우에도 알려지지 않은 객체 범주를 발견하는 것을 목표로 하며, 로봇 공학 및 자율주행과 같은 응용 분야에서 큰 잠재력을 가지고 있다.
'DL > Object detection' 카테고리의 다른 글
| M2Det(M2Det: A Single-Shot Object Detector based on Multi-level Feature Pyramid Network) (2) | 2024.01.22 |
|---|---|
| YOLO v3 (0) | 2024.01.22 |
| Mask R-CNN (0) | 2024.01.18 |
| FPN (Feature Pyramid Networks for Object Detection) (0) | 2024.01.17 |
| YOLO v2 (1) | 2024.01.15 |



