FPN의 한계
- FPN은 classification task를 위해 설계된 backbone network로부터 Multi-scale feature maps를 추출하는데, 이를 통해 구성된 Feature Pyramid는 객체 인식 task를 수행하기 위해 충분히 representative하지 않다.
- Feature Pyramid의 각 Level의 feature map들은 주로 backbone network의 single-level-layer로부터 구성되어있고, 이로 인해 객체의 외형에 따른 인식 성능의 차이가 발생한다.
일반적으로 더 깊은 layer의 high-level feature는 classification task에 적합하고, 얕은 Layer의 low-level feature는 localization task에 더 적합하다. 이 밖에도 전자는 복잡한 외형의 Feature를 포착하는데 유리하고, 후자는 단순한 외형을 파악하는데 유리하다.
현실의 데이터들은 비슷한 크기를 가지지만 객체의 외형의 복잡한 정도는 상당히 다를 수 있다. 따라서 FPN처럼 single-level layer로 구성되어 있다면 크기가 비슷하면서 외형의 복잡도가 다른 두 객체를 모두 포착하지 못할 수 있다.
Preview

위에서 언급한 FPN의 한계점을 보완하기 위해 보다 효율적인 feature pyramid를 설계하는 MLFPN(Multi-level feature pyramid network)를 제안한다. MLFPN은 세 모듈로 구성되어 있다. FFM(Feature Fusion Module)은 backbone network로부터 high와 low level feature를 fuse하여 base feature를 생성한다. TUM(Thinned U-shape Module)은 서로 다른 크기를 가진 Feature map을 생성하고, FFMv2는 base feature와 이전 TUM의 가장 큰 scale의 feature map을 Fuse하고, 그 다음 TUM에 입력한다. 마지막으로 SFAM(Scale-wise feature Aggregation Module)은 multi-level, multi-scale features를 scale-wise feature concatenation과 channel-wise attention 메커니즘을 통해 결합한다. 최종적으로 MLFPN과 SSD를 결합하여 M2Det라는 end-to-end one-stage detector를 설계한다.
Main Ideas
MLFPN(Multi-Level feature pyramid Network)
MLFPN은 multi-level, multi-scale feature map을 구성하는 네트워크로 3가지 모듈인 FFM, TUM, SFAM으로 구성되어 있다.
1. FFM(Feature Fusion Module)

FFM은 네트워크의 서로 다른 feature들을 융합하고, 이것으로 최종 multi-level feature pyramid를 설계하는데 중요한 역할을 한다. 같은 역할을 수행하지만 다른 구조를 가진 v1과 v2가 있다.
FFMv1은 backbone network로부터 두 개의 서로 다른 scale을 가지는 Feature map을 추출해 fuse한 후 base feature map을 생성한다. 그림(a)와 같이 각각의 feature map에 conv 연산을 적용하고, scale이 작은 feature map을 upsample시켜 concat하여 하나의 feature map을 얻는다.
FFMv2는 FFMv1이 생성한 base feature에 대하여 conv 연산을 적용한 후 이전 TUM의 가장 큰 scale의 Feature map(마치 RNN모듈의 hidden state처럼 정보를 전달하는 것 같다.)을 입력받아 concat한 후 다음 TUM에 전달한다(b). 이 때 입력으로 사용되는 feature map의 scale은 같다.
2. TUM(Thinned U-shape Module)
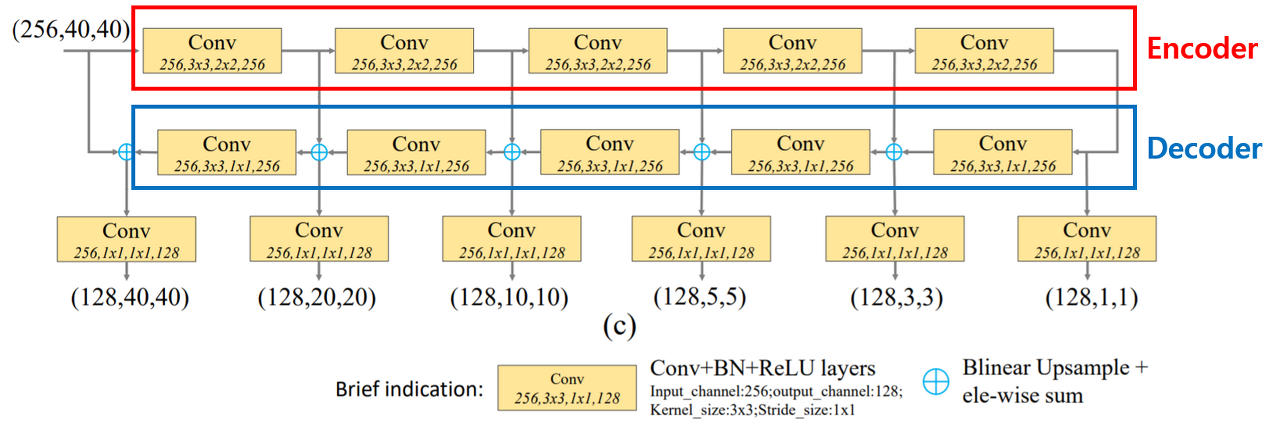
TUM은 입력받은 feature map에 대하여 multi-level feature map을 생성하는 역할을 수행하며, Encoder-Decoder 구조로 U자형 구조를 가진다.
Encoder network에서는 입력받은 feature map에 대하여 3x3 conv 연산을 적용해 scale이 다른 다수의 feature map(E1, E2, E3, E4, E5)을 출력한다.
Decoder network에서는 Encoder network에서 출력한 다수의 feature map에 대하여 더 높은 level(scale이 더 작은)에 대하여 Upsample한 후 바로 아래 Level의f feature map과 element-wise하게 더해준 후 1x1 conv 연산을 수행한다. 이를 통해 최종적으로 scale이 다른 다수의 feature map(D1, D2, D3, D4, D5)를 출력한다.
MLFPN 내부에서 TUM과 FFM은 서로 교차하는 구조를 가진다. FFMv에서 얻은 base feature map을 첫 TUM에 입력해 feature map을 얻고, FFMv2를 통해 fuse한 후 두 번째 TUM에 입력하고, 이러한 과정을 반복한다. 논문에서는 총 8개의 TUM을 사용한다.
각 TUM의 출력은 입력으로 주어진 feature map의 level에 대한 Multi-scale feature map에 해당한다. 즉 초반의 TUM은 shallow-level feature, 중간은 medium-level feauture, 후반은 deep-level feature를 제공한다.
3. SFAM(Scale-wise feature Aggregation Module)
SFAM은 TUM에 의해 생성된 multi-level, scale faeture를 scale-wise feature concatenation과 channel-wise attention 메커니즘을 통해 집계하여 multi-level feature pyramid로 구성하는 역할을 수행한다.

3.1) Scale-wise feature concatenation

Scale-wise feature concatentaion은 말 그대로 TUM의 output에서 같은 scale별로 Feature map을 concat한다고 보면 된다. 위의 예시처럼 concat이 진행될 경우 3개의 scale이 다른 feature map이 형성된다.
실제 논문에서는 8개의 TUM에서 각각 6개의 서로 다른 scale의 feature map을 출력한다고 한다. 따라서 실제 이 과정을 수행하면 최종적으로 6개의 multi-level, multi-scale feature map을 출력한다.
3.2) Channel wise attention
논문에서는 단순히 Scale-wise feature concatentaion만으로 충분히 adaptive하지 않다고 언급한다. Channel-wise attention 모듈은 feature가 가장 많은 효율을 얻을 수 있는 channel에 집중하도록 설계하는 작업을 수행한다. 여기서는 Scale-wise feature concat과정에서 출력된 Feature map을 SE(Squeeze Excitation) Block에 입력한다.

SE block은 CNN에 부착하여 사용할 수 있는 block으로 연산량을 크게 늘리지 않으면서 정확도를 향상시킨다. SE block은 다음과 같은 step으로 구성되어 있다.
- Squeeze step : 입력으로 들어온 hxwxc 사이즈의 Feature map에 대해 GAP를 수행한다. 이를 통해 각 channel을 하나의 값으로 표현한다.
- Excitation step : 1에서 얻은 1x1xc 크기의 Feature map에 대하여 2개의 fc layer를 적용해 channel 별 상대적 중요도를 구하는데, 이 때 마지막 layer의 activation function은 sigmoid이다. 이를 통한 최종 Output은 각 channel 별 0~1 사의 값으로, 이것으로 해당 channel별 중요도를 파악하는 것이 가능해진다.
- Recalibration step : 앞에서 구한 channel 별 중요도와 원본 Feature map을 channel별로 곱해 channel별 중요도를 재보정 해준다.
Training M2Det
1) Extract two feature maps from backbone network
- backbone network로부터 다른 level에서 다른 scale을 가진 두 개의 Feature map을 추출한다. 여기서 backbone으로는 VGG 또는 ResNet을 사용한다.
2) Generate Base feature map by FFMv1
- FFMv1을 통해 두 개의 Feature map을 fuse시켜 하나의 base Feature map을 생성한다.
3) Generate Multi-level, Multi-scale feature maps by jointly alternating FFMv2 and TUM
- Base feature map을 첫 TUM에 입력해 multi-level, multi-scale feature map을 얻는다. 그리고 TUM에서 얻은 feature map 중에서 가장 Scale이 큰 Feature map과 base feature map을 통해 FFMv2를 통해 Fuse한다. fuse된 feature map은 다음 TUM에 입력된다. 논문에서는 TUM 수를 8개로 설정했다.
4) Construct Final Feature pyramid by SFAM
- 앞서 얻은 8개의 multi-level, multi-scale feature maps를 scale-wise feature concatenation 과정을 통해 결합한다. 이 후 SE block을 사용해 재보정된 6개의 feature map으로 구성된 pyramid를 얻는다.
5) Prediction by classification branch and bbox regression branch
- Feature pyramid 각 level 별 Feature map을 두 개의 병렬로 구성된 conv layer에 입력해 class score와 bbox regressor를 얻는다.
Detection
- 실제 detection 시에는 모델이 예측한 bbox에 대하여 soft-NMS를 적용해 최종 prediction을 출력한다.

M2Det은 MS COCO 데이터셋 실험 결과 pytorch 최적화 기능을 수행하여 15.8FPS라는 속도를 달성했다. 또한 AP값은 44.2%를 보이면서 당시 모든 One-stage detector의 성능을 뛰어넘었다.

M2Det의 가장 큰 기여는 multi-scale뿐만 아니라 multi-level로 구성된 feature pyramid를 설계했다는 점이다. 이는 객체의 회영이 복잡한 경우를 처리하는데 유용하게 사용될 수 있다.
논문에서는 다양한 scale과 외형 변화를 잘 포착할 수 있음을 보이기 위해 classification 시 Feature map의 activation value를 살펴보았다. 위의 입력 이미지를 보면 사람 객체 2, 차 객체 2, 신호등 객체 1이 있는데, 각각의 class마다 객체의 크기가 다르다. 의의 활성화 정도를 통해 알 수 있는 사실은 다음과 같다.
- 작은 사람과 작은 차는 큰 크기의 feature map에서 강한 활성화 정도를 보이는 반면, 큰 사람과 큰 차는 작은 크기의 feature map에서 같한 활성화 정도를 보인다. 이는 Multi-scale feature가 객체의 크기를 잘 포착하고 있음을 나타낸다.
- 신호등, 작은사람, 작은 차는 같은 feature map에서 큰 activation value를 가진다. 이는 세 객체가 서로 비슷한 크기이기 때문이다.
- 사람, 차, 신호등은 highest-level, middel-level, lowest-level feature map에서 가장 큰 activation value를 가진다. 이는 객체 외형의 복잡도를 Multi-level feature가 잘 포착하고 있음을 의미한다.
즉 위의 예시를 통해 M2Det은 객체의 크기와 외형의 복잡도라는 특징을 잘 포착하고 있음을 알 수 있다.
'DL > Object detection' 카테고리의 다른 글
| EfficientDet (0) | 2024.01.24 |
|---|---|
| YOLO v4: Optimal Speed and Accuracy of Object Detection (0) | 2024.01.24 |
| YOLO v3 (0) | 2024.01.22 |
| [논문 리뷰] Object Detection in 20 Years: A Survey (0) | 2024.01.19 |
| Mask R-CNN (0) | 2024.01.18 |



