반응형
분류 문제에 있어서 데이터에 불균형이 있다면 소수의 이상 데이터를 분류해내는 문제에서 정확도를 높이기 쉽지 않다. 이 때 소수의 범주 데이터의 수를 늘리는 오버샘플링과 상대적으로 많은 데이터의 일부만 사용하는 언더 샘플링을 사용해 보완할 수 있다.
1. 언더 샘플링
언더 샘플링을 사용하면 데이터 불균형으로 인한 문제는 피할 수 있지만 전체 데이터의 수가 줄어들어 학습 성능을 떨어뜨릴 수 있다.
## RandomUnderSampling
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from collections import Counter
from imblearn.under_sampling import RandomUnderSampler
# 95:5의 불균형 데이터 생성
x, y = make_classification(n_samples=2000, n_features = 6, weights = [0.95], flip_y = 0)
print(Counter(y))
undersample = RandomUnderSampler(sampling_strategy = 'majority') # sampling_strategy = 'majority' 시 소수 레이블의 데이터 수에 맞춰줌
undersample2 = RandomUnderSampler(sampling_strategy = 0.5) # 소수 레이블의 데이터 수의 상대적인 비율
x_under, y_under = undersample.fit_resample(x, y)
x_under2, y_under2 = undersample2.fit_resample(x, y)
print(Counter(y_under))
print(Counter(y_under2))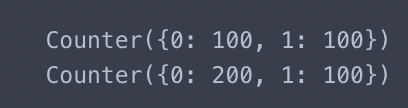
2. 오버샘플링
오버샘플링은 소수 레이블의 데이터를 다수 레이블을 지닌 데이터 수만큼 증식시키는 방법이다. 데이터의 손실이 없어 일반적으로 언더 샘플링보다 성능에 유리해 주로 사용된다.
2.1. Random Over Sampling
Random Over Sampling은 소수 레이블의 데이터를 단순 복제하여 다수 레이블의 데이터와 비율을 맞춘다. 분포가 변하지 않지만 그 수 가 늘어나 가중치를 받을 수 있다. 소수 레이블에 대한 과적합 위험이 있지만 불균형 문제를 처리하지 않는 것보다 유효해 종종 사용된다.
## RandomOverSampling
from imblearn.over_sampling import RandomOverSampler
oversample = RandomOverSampler(sampling_strategy = 'minority') # sampling_strategy = 'minority' 시 다수 레이블의 데이터 수에 맞춰줌
oversample2 = RandomOverSampler(sampling_strategy = 0.5) # 소수 레이블의 데이터 수의 상대적인 비율
x_over, y_over = oversample.fit_resample(x, y)
x_over2, y_over2 = oversample2.fit_resample(x, y)
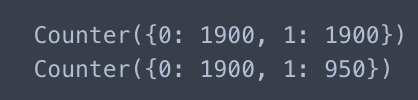
print(Counter(y_over))
print(Counter(y_over2))
2.2 SMOTE
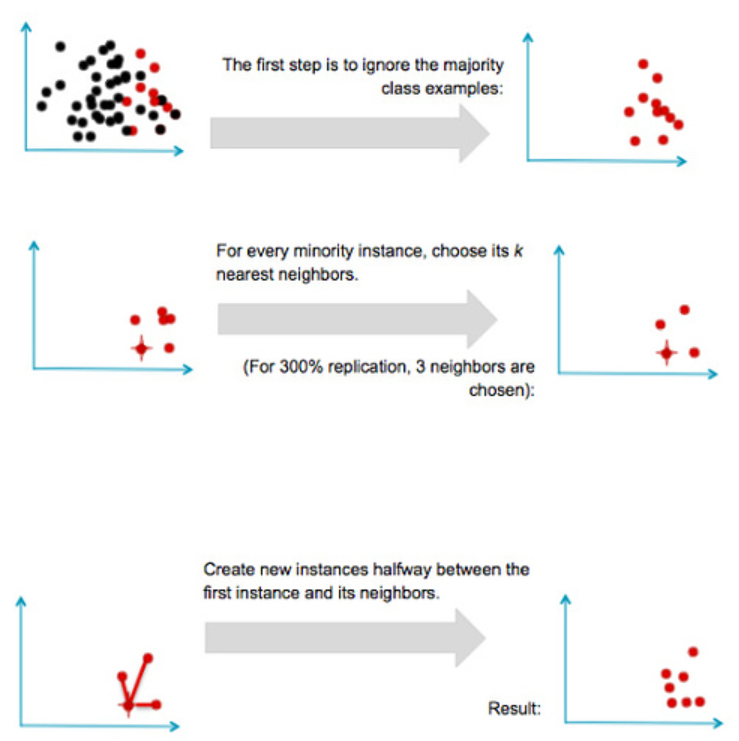
SMOTE는 KNN 알고리즘을 활용해 관측 값과 이웃으로 선택된 값 사이에 임의의 새로운 데이터를 생성하는 기법이다.
from imblearn.over_sampling import SMOTE
smote_sample = SMOTE(sampling_strategy = 'minority')
x_sm, y_sm = smote_sample.fit_resample(x, y)
print(Counter(y_sm))
3. 산포도를 통한 전체 기법 비교
from matplotlib import pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
sns.scatterplot(x[:, 1], x[:, 2], hue=y, ax=axes[0][0], alpha=0.5)
sns.scatterplot(x_under[:, 1], x_under[:, 2], hue=y_under, ax=axes[0][1], alpha=0.5)
sns.scatterplot(x_over2[:, 1], x_over2[:, 2], hue=y_over2, ax=axes[1][0], alpha=0.5)
sns.scatterplot(x_sm[:, 1], x_sm[:, 2], hue=y_sm, ax=axes[1][1], alpha=0.5)
axes[0][0].set_title('Original Data')
axes[0][1].set_title('Random Under Sampling')
axes[1][0].set_title('Random Over Sampling')
axes[1][1].set_title('SMOTE')
plt.show()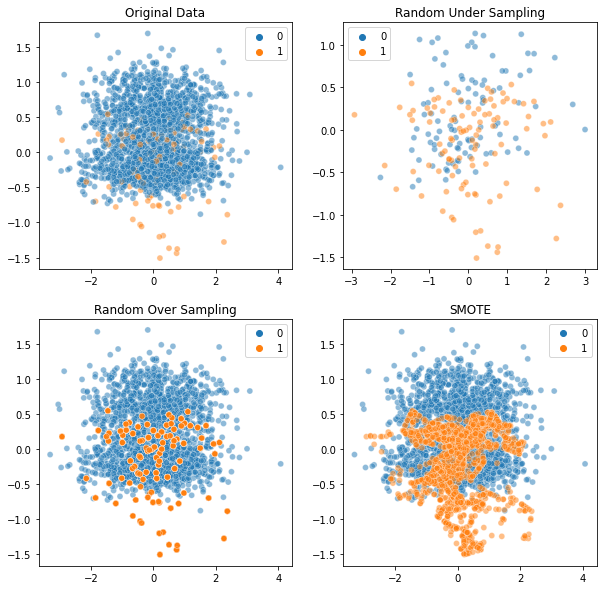
반응형
'ADP로ML정리' 카테고리의 다른 글
| 4-1. 회귀 모델 - 규제가 있는 선형 회귀 (1) | 2024.02.19 |
|---|---|
| 3. 머신러닝 평가지표 (0) | 2024.02.15 |
| 2-5. 데이터 전처리 - 차원축소 (0) | 2024.02.14 |
| 2-4. 데이터 전처리 - 데이터 분할 및 스케일링 (1) | 2024.02.14 |
| 2-3. 데이터 전처리 - 범주형 변수 처리 (0) | 2024.02.14 |



