NLP란
NLP란 자연어 처리란 뜻으로, 자연어 생성(Meaning ->Text)과 자연어 이해(Text -> Meaning) 두 가지를 포함하는 영역입니다.
NLP의 영역
- 감정 분석(Sentiment Analysis)
- 요약(Summarization)
- 기계 번역(Machine Translation)
- 질문 응답(Question Answering)
문자를 숫자로 표현하는 법
Token과 vocabulary
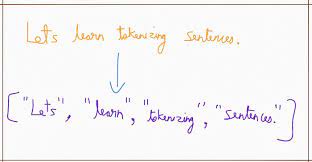
각 Token별로 indexing했을 때 문제점
1) feature engineering의 label encoding처럼 별 의미 없을 듯??
2) 학습한 말뭉치에 없는 Token이 나온다면?? -> OOV(Out-Of-Voca)
OOV문제를 줄이기 위해 큰 기업의 연구에서는 말뭉치(Corpus)를 잘 or 크게 만들어 공개하기도 함
1. Character based tokenization

장점
1) Token Vocabulary 크기가 줄어든다.
2) 모든 글자를 표현할 수 있다. (사실상 OOV가 없어짐)
단점
1) 표현법에 대한 학습이 어렵다
2. n-gram Tokenization
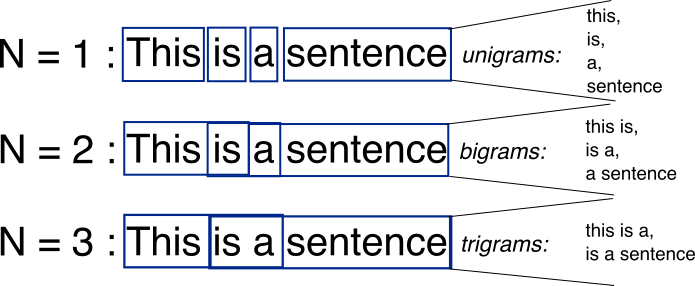
합성곱연산의 필터적용으로 생각하면, n이 윈도우 크기, stride는 1로 고정
장점
1) 연속적으로 자주 쓰이는 언어를 잡아낼 수 있음 (ex. "this is")
단점
1) 쓸모없는 조합이 많이 생성된다.
2) Token이 과하게 커진다.
3. BPE(Byte Pair Encoding)

자주 나오는 데이터의 연속된 패턴을 치환하는 방식!
BPE 진행 방식
1) 단어 횟수를 기록한 사전을 만든다
2) 연속된 2개의 글자의 수를 세 가장 많이 나오는 조합을 찾는다
3) 정해 놓은 횟수만큼 2~3번 반복한다.
Word Embedding
워드 임베딩(Word Embedding)은 단어를 벡터로 표현하는 방법이다!
1) 원-핫 인코딩

2) Frequency-based Method
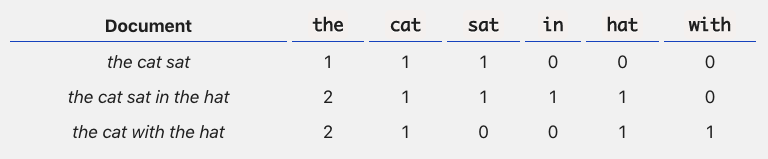
the, a , an 자주 나오는 단어에 대한 해결법 -> TF - IDF (단어 빈도수 X 단어의 역빈도수)
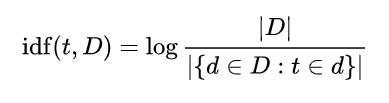
그래도 Frequency-based Method는 단어의 순서 즉 맥락을 무시한다는 점에서 새로운 문장을 생성하는 Task에서는 사용하기 어렵다!
Word2vec
이름 그대로 word를 벡터(숫자형태)로! -> "Token의 의미는 주변 Token의 정보로 표현된다"라고 가정
즉, 단어는 맥락으로 결정된다

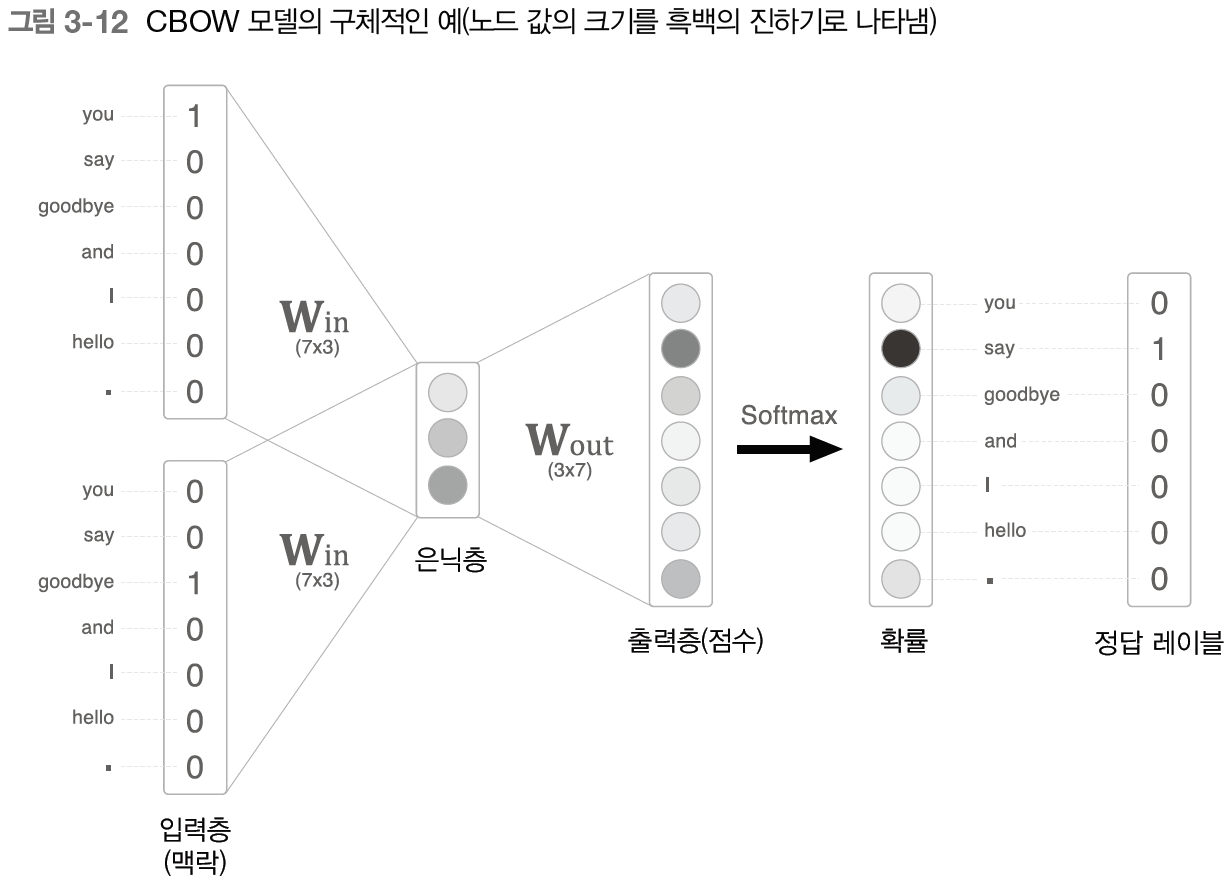
CBOW 특징
1) 각 단어들을 원-핫 인코딩한다.
2) 맥락의 크기에 따라 입력계층 수가 정해진다.(위 예시는 앞 뒤 한 단어씩 선택해 입력계층이 2개!)
3) W_in을 공유한다(W_in은 모두 같다)
4) 서로 다른 입력계층에서 들어온 값들은 평균되어 은닉층에 전달된다
Word2vec의 개선
1. 과다한 메모리와 계산량
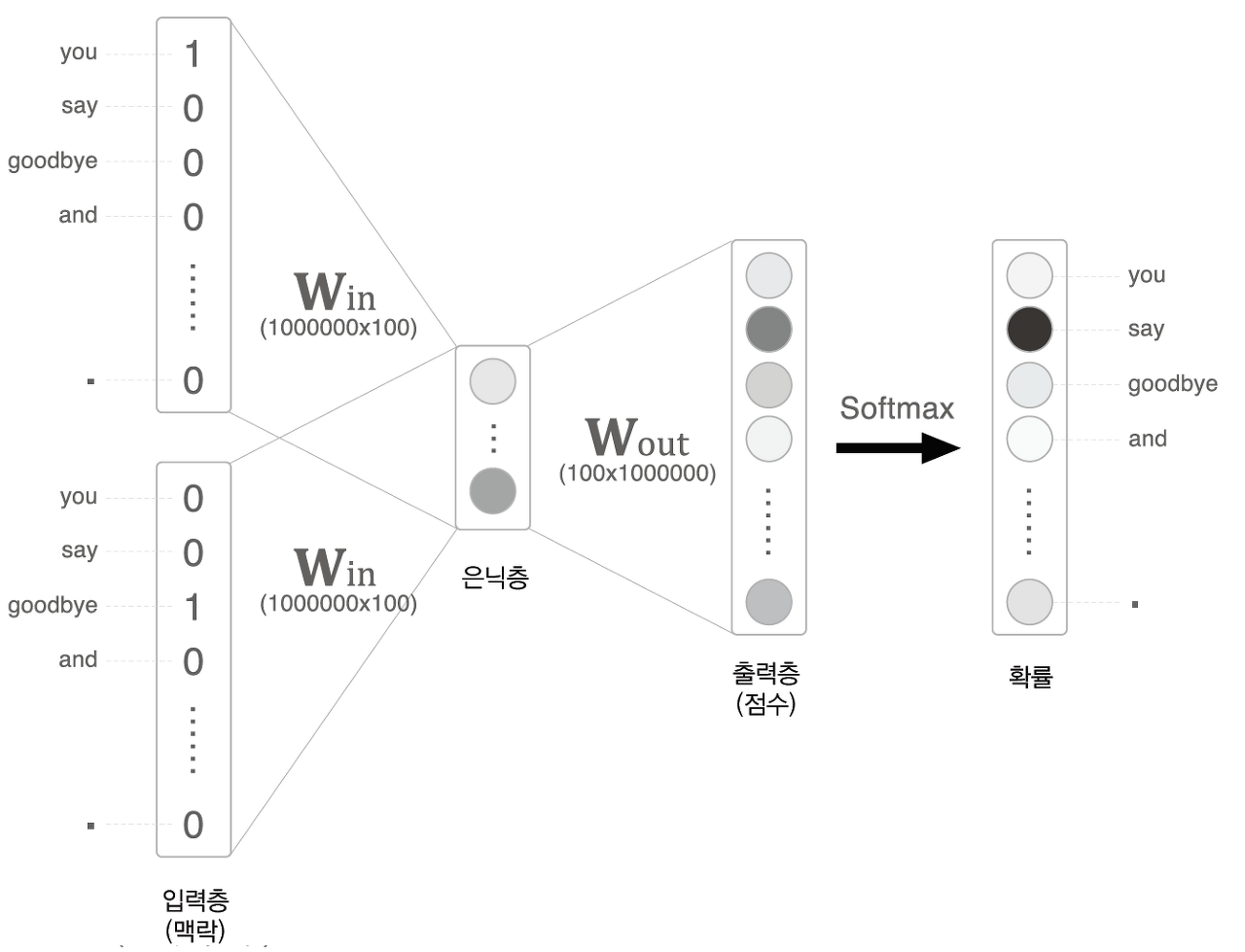
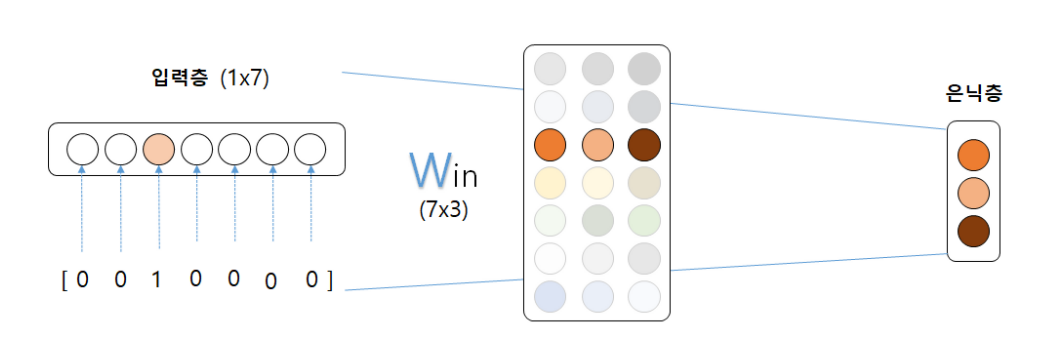
Embedding layer
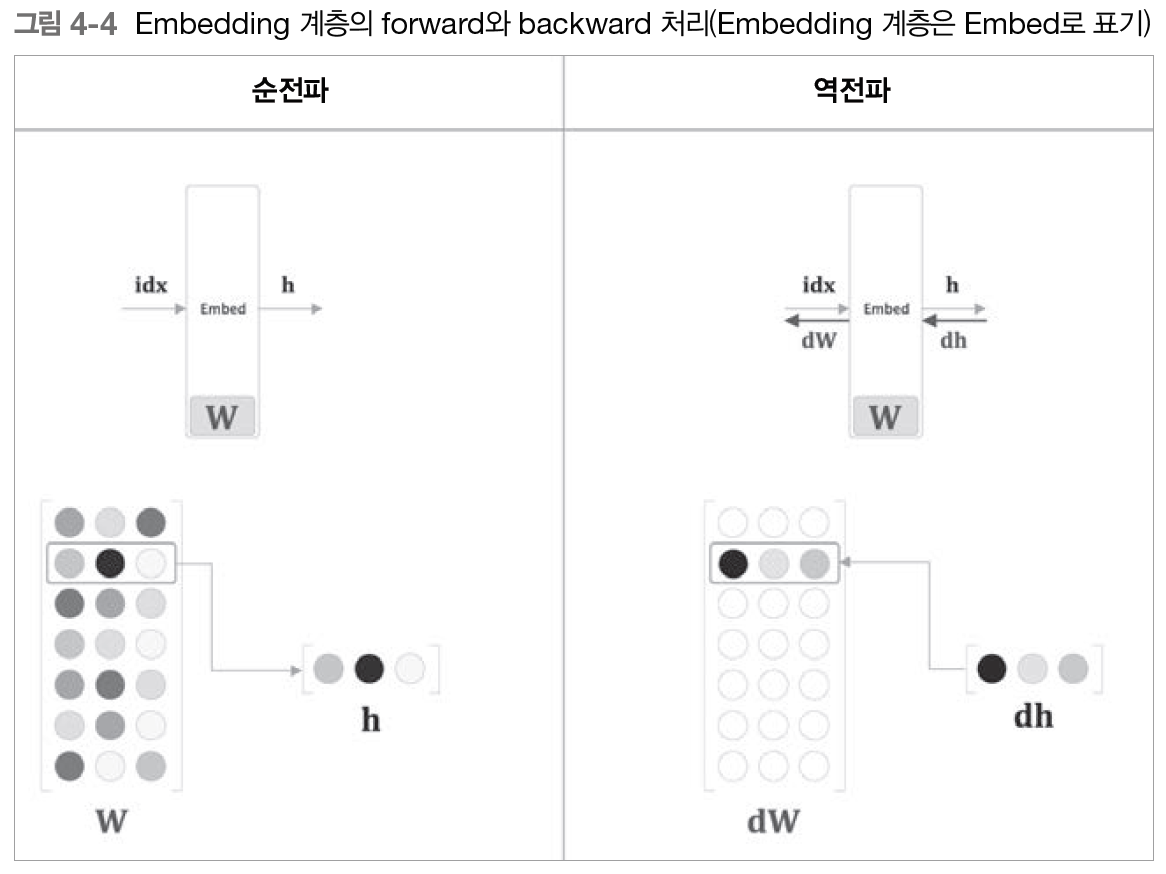
위 그림의 dW는 W와 크기가 같은 영행렬이다. 근데 한 번에 들어온 여러 idx에 중복이 있다면?
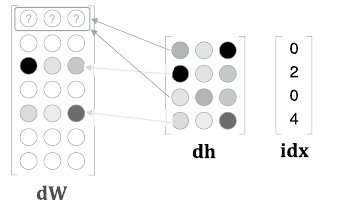
dW에 할당이 아닌 +를 해야 중복된 idx의 미분값들이 가중치 업데이트 시 모두 반영될 수 있음
2. 은닉층-출력층 행렬곱과 Softmax 계산
다중분류이기 때문에 일어나는 문제점이다!! 다중분류를 이진분류로 바꿔서 간단하게 생각해보면

확률값을 뽑을 때 정답인 say에 대한 건 무조건 뽑아야되는 것 같은데.. 나머지는 모두 다 가지고 가야되나?
Negative sampling

(정답인 경우의 이진분류 + 샘플링된 정답이 아닌 경우)로 충분히 학습할 수 있다!
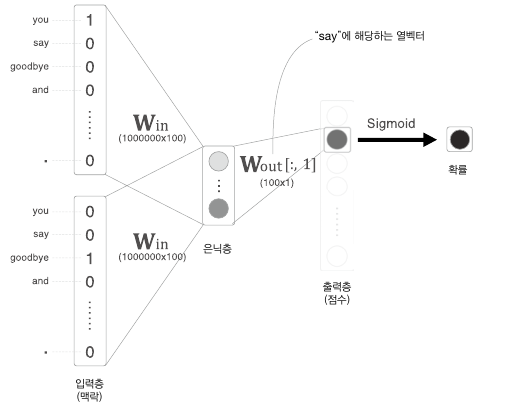
따라서 위 그림처럼 정답인 경우와 샘플링된 정답이 아닌 경우들에 대해서만 은닉층-출력층 사이에 Embedding 계층을 사용하고, softmax를 sigmoid로 대체한다!
Negative sampling기법
-> 모든 단어가 균일한 확률로 sampling되면, 우연히 희소한 단어가 sampling되었을 때 학습결과가 나빠질 것이다
-> 따라서 말뭉치에서 각 단어의 출현 횟수 확률분포로 sampling한다
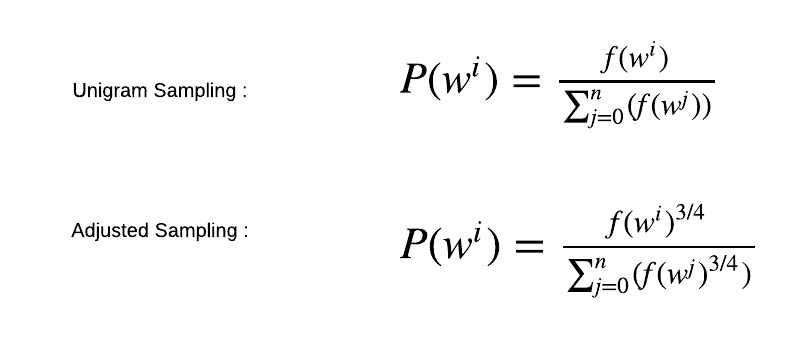
-> 확률분포에 0.75를 제곱해 확률이 낮은 단어의 확률을 살짝 더 높인다
skip gram 모델
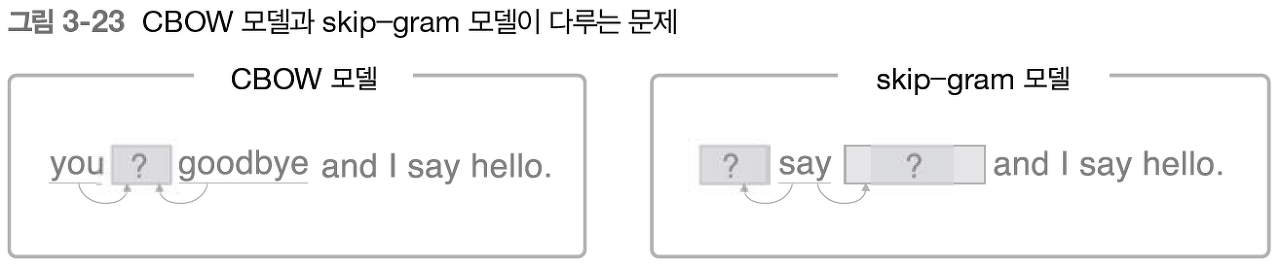
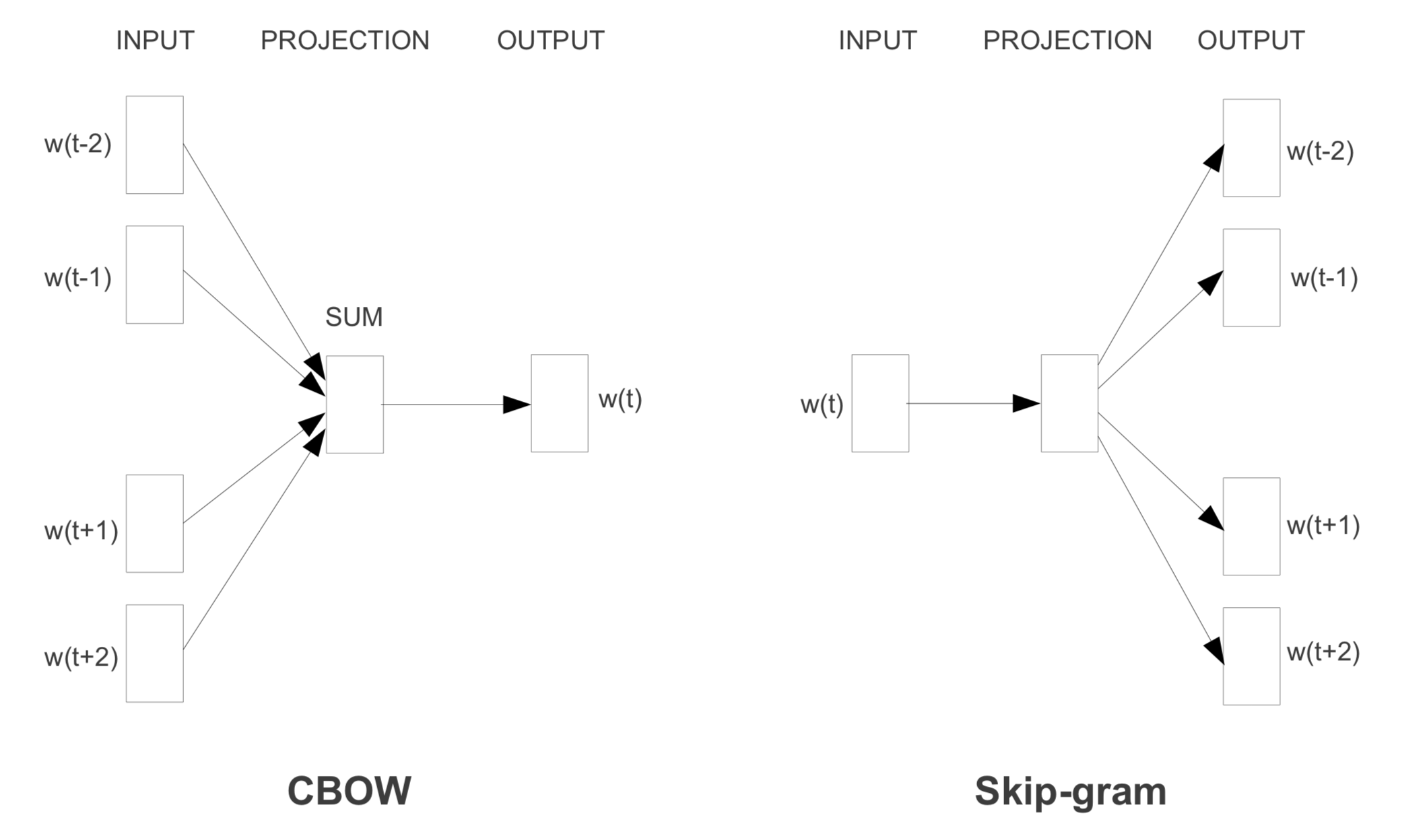
CBOW와 반대로 단어로부터 맥락을 예측한다!
-> CBOW 한 윈도우를 한 번 학습하지만, Skip-gram은 한 단어로 Context Token을 모두 예측하는 방식이라 학습 횟수가 더 많아 느리다
-> 하지만 CBOW처럼 분산표현을 평균내는 부분이 없어 희소한 단어에 더 좋은 성능을 보여준다
Pre-trained Word Embedding
GloVE
- 기존의 표현법에서 사용한 문서 내 모든 단어의 통계 정보와 Word2vec의 Local Context Window 정보를 동시에 사용하는 모델링
fasttext
- 1개의 word에 대한 vector로 n-gram character에 대한 vector 평균을 사용
BERT
- 문맥에 따라 단어의 Embedding Vector가 바뀔 수 있는 Contextual Embedding 사용
모델링 방법들 뿐만 아니라 "잘 만들어 놓은 큰 Corpus" 역시 중요하기 때문에 큰 기업이 만든 Pre-trained Word Vector를 가져다 쓰는 것이 NLP연구를 하는 데 꼭 필요한 요소이다!
'AI_basic > Deeplearning' 카테고리의 다른 글
| [Deeplearning Part. 8-2] LSTM (0) | 2022.01.25 |
|---|---|
| [Deeplearning Part.8-1] RNN 기본구조 (0) | 2022.01.24 |
| [Deeplearning Part .6-1] CNN (2) | 2022.01.09 |
| [Deeplearning Part.5] 학습 관련 기술들 (1) | 2022.01.09 |
| [Deeplearning Part.4] 오차역전파법 (2) | 2022.01.06 |



