이 전에 알아본 Word2vec의 CBOW모델을 다시보면, 맥락 안의 단어 순서가 무시된다는 단점이 있습니다.
예시로 나온 문장 중 say에 대한 윈도우는 "you say goodbye"가 되는데, 이는 (you, say)와 (say, you)를 같은 맥락으로 취급합니다.
따라서 맥락 내의 단어 순서도 고려한 모델이 바람직한데, 여기서 등장하는 것이 순환 신경망(Recursive Neural Network)입니다.
RNN

t는 각 단어의 순서를 기준으로 인덱싱 한 숫자입니다. 우변을 좌변처럼 하나의 계층으로 본다면 RNN으로 표시된 사각형의 층을 지나서 나온 output이 계속해서 다시 RNN계층으로 들어가게 됩니다. 따라서 값이 계속 순환하고 있습니다!

RNN한 계층의 계산수식을 보면, 이전 RNN계층으로부터 나온 h(t-1)과 가중치행렬과의 곱, 현재 RNN계층의 input과 가중치 행렬과의 곱, 편향 이렇게 세 항이 더해지고 이 값이 탄젠트 함수를 거쳐 output으로 출력됩니다.
이것을 다른 관점으로 보면, h가 RNN계층의 "상태"를 가지고 있으며, 위 계산수식으로 갱신되는 형태입니다. 따라서 많은 문헌에서 RNN의 출력 h를 은닉상태 혹은 은닉 상태 벡터라고 합니다.
BPTT
BPTT는 Backpropagation Through Time의 줄임말로, 시간(단어의 순서) 방향으로 펼친 신경망의 오차역전파법을 의미합니다.
그런데 이 시계열 데이터의 시간 크기가 커지면, BPTT과정에서 연산량이 많아집니다. 따라서 큰 시계열 데이터를 취급할 때는 신경망의 연결을 적당한 길이로 끊어 오차역전파법을 수행합니다. 이를 Truncated BPTT라고 합니다.
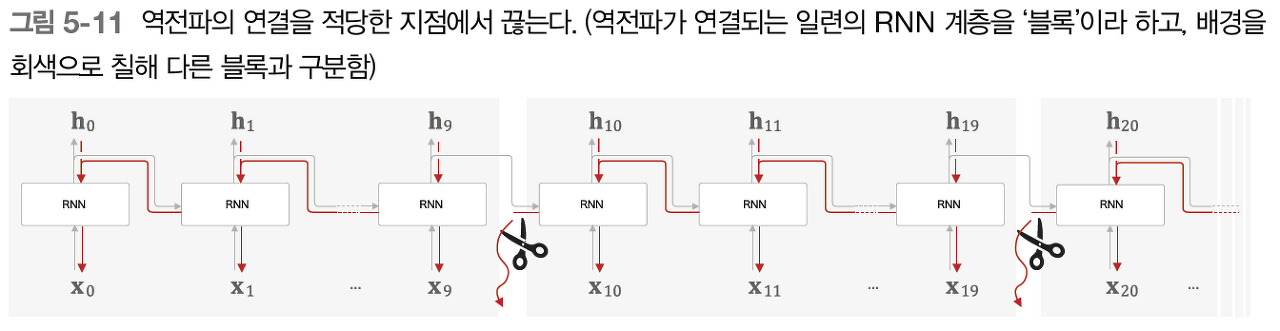
여기서 중요한 점은 Truncated BPTT는 순전파가 아닌 "역전파의 흐름만!!" 적당히 끊는다는 것입니다.
그림을 보면 순전파에서의 h값들은 블럭이 달라져도 계속 전달되는 것을 알 수 있습니다. 따라서 이 방법을 사용해도 input data는 순서대로 넣어야합니다!!

여기서 중요한 점은 Truncated BPTT는 순전파가 아닌 "역전파의 흐름만!!" 적당히 끊는다는 것입니다.
Truncated BPTT에서 알아둬야할 점은 미니배치 학습 시 배치를 순서 기준으로 자르고, 미니배치별로 데이터를 제공하는 시작 위치를 옮겨야 합니다.

Time RNN


RNN t개 분의 작업을 한꺼번에 처리하는 계층을 Time RNN이라고 합니다(첫번째 그림 속 사각형). Time RNN계층을 하나의 층으로 생각했을 때, 각 층마다 나온 h는 인스턴스 변수로 유지합니다.
순전파와 역전파 모두 각 값들을 벡터형태로 모아둔 거나 다름없기 때문에, 큰 어려움 없이 미니배치 중 하나라고 생각하고 이해했습니다.
TIME 계층 구현

좌변처럼 층을 모아서 한 번에 처리하면, 행렬 계산을 사용해 효율성있게 모델을 구현할 수 있습니다.
'AI_basic > Deeplearning' 카테고리의 다른 글
| [Deeplearning Part.8-3] seq2seq (1) | 2022.01.25 |
|---|---|
| [Deeplearning Part. 8-2] LSTM (0) | 2022.01.25 |
| [Deeplearning Part.7-1] 자연어 처리와 Word Embedding (0) | 2022.01.22 |
| [Deeplearning Part .6-1] CNN (1) | 2022.01.09 |
| [Deeplearning Part.5] 학습 관련 기술들 (0) | 2022.01.09 |



