기본 구조의 RNN의 문제점
1. 기울기 소실

기울기 소실의 원인은 tanh함수입니다. tanh는 ouput의 절대값이 1보다 작아 역전파 시 기울기가 소실될 수 있습니다. 이 문제 때문에 기본 DNN모델이나 CNN에서 활성화함수로 sigmoid를 ReLU로 대체하는 것을 알 수 있었습니다.
2. 기울기 폭발(소실 포함)
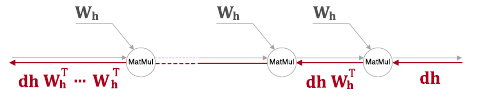
기울기 폭발의 원인은 가중치 행렬과의 행렬곱입니다. W라는 가중치는 모든 시점에서 공유되는데, 자세한 부분은 https://yjjo.tistory.com/15를 참고하면 좋을 것 같습니다.
W라는 가중치가 모든 시점에서 공유되기 때문에, 역전파가 하류로 갈수록 W의 전치가 계속해서 곱해져갑니다. 이 때, 행렬의 특잇값이 1보다 크다면 제곱 할수록 계속해서 커져 기울기 폭발이 일어납니다. 또한 1보다 작을 경우 0에 수렴하게 되어 기울기 소실이 일어납니다.
LSTM
위에서 알아본 기울기 소실 문제를 해결할 모델이 등장했습니다! RNN에 "게이트"라는 장치를 추가해 위 문제를 해결하고자 제안된 많은 신경망이 있는데 그 중 대표적인 것이 LSTM과 GRU입니다.

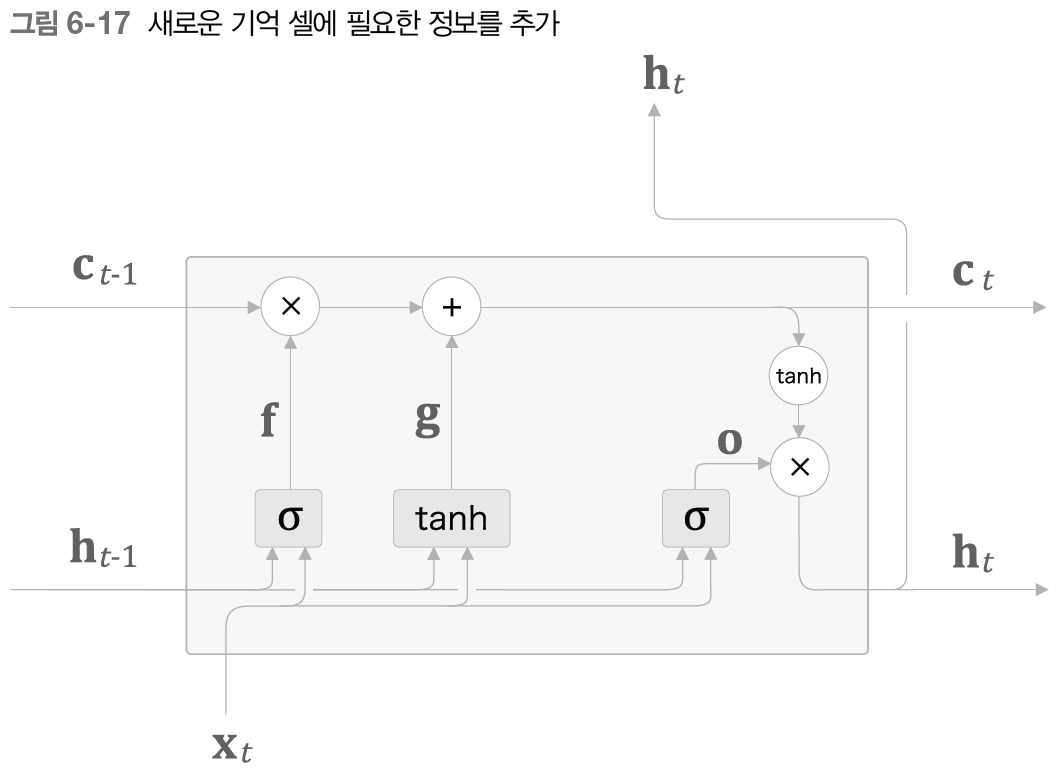
LSTM은 위 그림처럼 tanh를 적용하기 이전의 값을 따로 c(기억 셀이라고 합니다)라는 경로로 출력합니다. 기억 셀 c는 LSTM계층 내에서만 연결되며, ht와는 원소의 개수가 같습니다(tanh만 적용을 안했기 때문)
위 그림을 자세히 보면, ht는 ct로부터 게산됨을 알 수 있습니다.
LSTM의 게이트
게이트는 문이라는 뜻으로, 문을 얼마나 여느냐에 따라 문을 지나가는 무언가의 양을 조절한다는 뜻으로 이해하면 됩니다. LSTM은 RNN에 몇 가지의 게이트를 더해 다음 층에 전달할 정보의 양(?)을 제어합니다. 또한, 얼마나 제어할지에 대해서도 알아서 학습할 수 있습니다!
이제 게이트를 위 그림에서 하나씩 추가해보면서 이해해보겠습니다
1. output 게이트

그림을 보면 현재 층의 input과 가중치행렬의 곱, 이전 층의 output과 가중치행렬의 곱, 그리고 편향이 더해진 값(o라고 부릅니다)이 시그모이드 함수를 지나 ht가 되려던 값에 곱해집니다.
위 층의 출력 ht는 tanh(ct)로 계산되는데, 이 tanh(ct)에 o가 곱해져(여기서의 곱은 행렬곱이 아닌 원소별 곱이 되는 아다마르 곱) ht가 나오는 형식인데, 이것은 "tanh(c)의 각 원소가 다음 층의 은닉 상태에 얼마나 중요한가"를 조정하는 장치로 o가 쓰이는 것을 알 수 있습니다.
(그림에서 생략되어있는데, 시그모이드 함수 이전에 각 요소들은 가중치행렬이 곱해지고, 편향과 함께 더해져 들어옵니다. 이는 이 후에 나오는 게이트도 마찬가지입니다.)
2. forget 게이트

"망각은 더 나은 전진을 낳는다", forget 게이트는 이전 층에서 흘러 들어온 기억 셀을 얼마나 받아들일지를 조정하는 장치입니다. 이 게이트의 ouput과 c(t-1)이 아다마르 곱됩니다!
2-1. 새로운 기억셀
forget 게이트라는 장치로 기억 셀에서 일정 부분이 삭제되었습니다. 따라서 새로 기억해야 할 정보를 기억 셀에 더해주는 장치를 추가합니다.
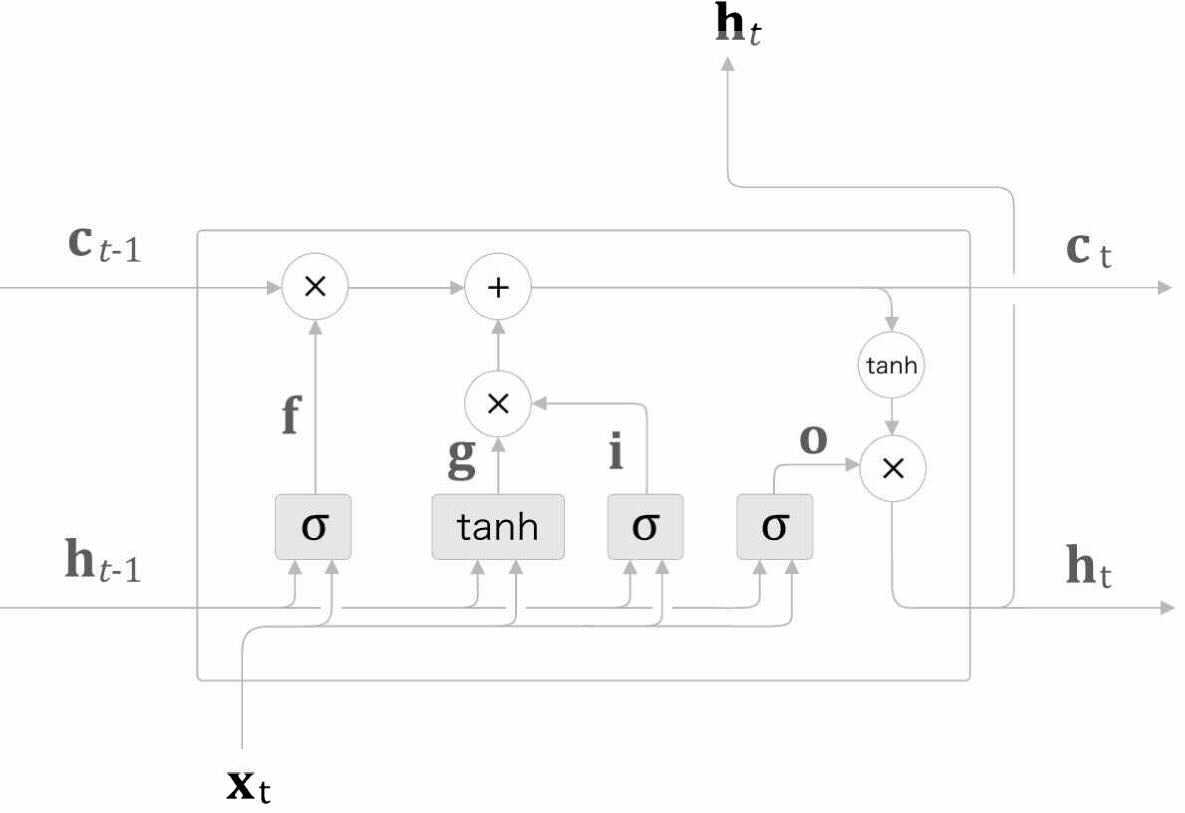
3. input 게이트
input 게이트는 2-1 새로운 기억 셀에서 추가되는 새로운 정보의 가치가 얼마나 큰지 판단하여 조정하는 장치입니다.
LSTM의 게이트로 기울기 소실을 해결할 수 있는 이유
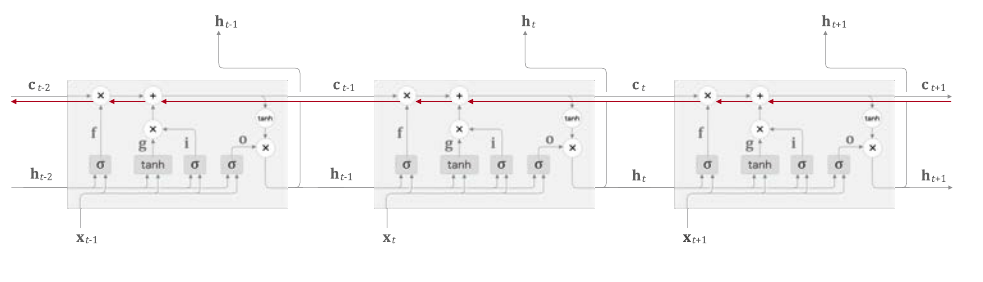
기억 셀 c에 집중해서 역전파의 흐름을 보면, c는 덧셈과 곱셈 노드밖에 지나지 않는데, 덧셈노드를 역전파로 지날 때는 상류의 값을 그대로 흘려보냅니다. (Deeplearning Part.4 오차역전파의 역전파 부분을 참고하세요!)
남은 것은 곱셈 노드인데, 행렬 곱이 아닌 아다마르 곱을 사용해 곱셈의 효과가 누적되지 않아 기울기 소실이 일어나지 않거나 일어나기 어려운 것입니다.
완성된 LSTM 기본구조
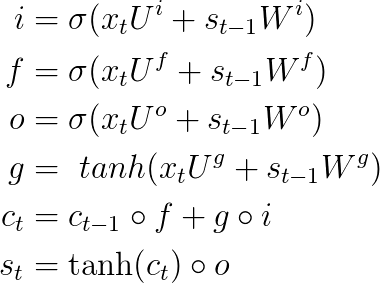
LSTM의 각 과정과 output출력을 수식으로 나타낸 것입니다

각 게이트 별 가중치들을 한 곳으로 모아 Affine 변환으로 계산할 수 있습니다! 각 게이트 별 출력값은 서로 다른 곳에 쓰이지만, 이렇게 모아서 한 번에 큰 행렬로 계산할 때가 더 빠릅니다. 또한, 가중치를 한 데로 모아 관리하게 되어 소스 코드도 간결해집니다.
미니배치를 고려한 Affine 변환 시의 형상 추이(편향 생략)

행렬의 형상을 잘 고려해서 보면 됩니다
N -> 배치 크기
D -> input 데이터 차원
H -> 은닉 상태의 차원
Time LSTM의 경우, 이전 글에서 봤던 TIME RNN의 RNN계층이 LSTM계층으로 바뀌고, 인스턴스 변수로 기억 셀이 추가된다는 것 외에 차이점은 없습니다.
또한 가중치공유, 정규화, 드롭아웃, 다층화 등을 통해 언어 모델을 개선하는 방법이 있는데, 이 부분은 나중에 따로 정리하겠습니다.
'AI_basic > Deeplearning' 카테고리의 다른 글
| [Deeplearning Part.8-4] GRU (1) | 2022.01.25 |
|---|---|
| [Deeplearning Part.8-3] seq2seq (1) | 2022.01.25 |
| [Deeplearning Part.8-1] RNN 기본구조 (0) | 2022.01.24 |
| [Deeplearning Part.7-1] 자연어 처리와 Word Embedding (0) | 2022.01.22 |
| [Deeplearning Part .6-1] CNN (2) | 2022.01.09 |



