1. 이산형 확률분포
확률변수는 일정한 확률을 가지고 발생하는 Event에 수치가 부여된 변수이다. 다양한 확률분포에서 확률 변수가 가질 수 있는 값이 이산형인 경우가 이산형 확률분포이다. 이 분포들의 확률값은 항상 0~1이며 모든 확률변수의 합은 1이다.
1-1. 베르누이 확률분포
동등한 실험 조건 하에서 실험의 결과가 두 가지의 결과만을 가질 때 이러한 실험을 베르누이 시행이라하고, 이 때 성공의 횟수를 확률변수 X라 할 때 확률변수 X는 성공률이 p인 베르누이 분포를 따른다고 한다. (동전 던지기 시행)
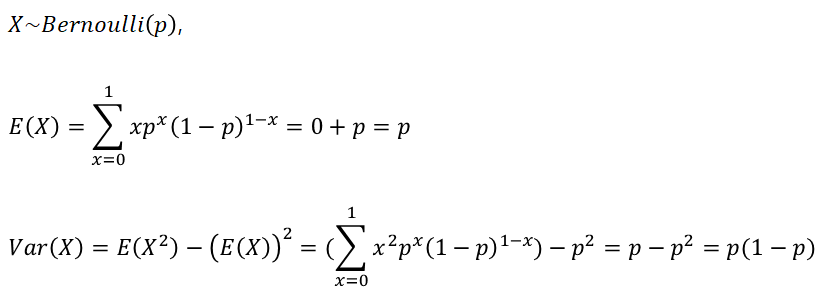
1-2. 이항분포
특정 실험에서 성공 확률이 p인 베르누이 시행을 독립적으로 n번 반복 시행했을 때 성공의 횟수를 확률변수 X라 하면 확률변수 X는 시행햇수 n과 성공 확률 p를 모수로 갖는 이항분포가 된다. (동전 던지기 n번 시행)
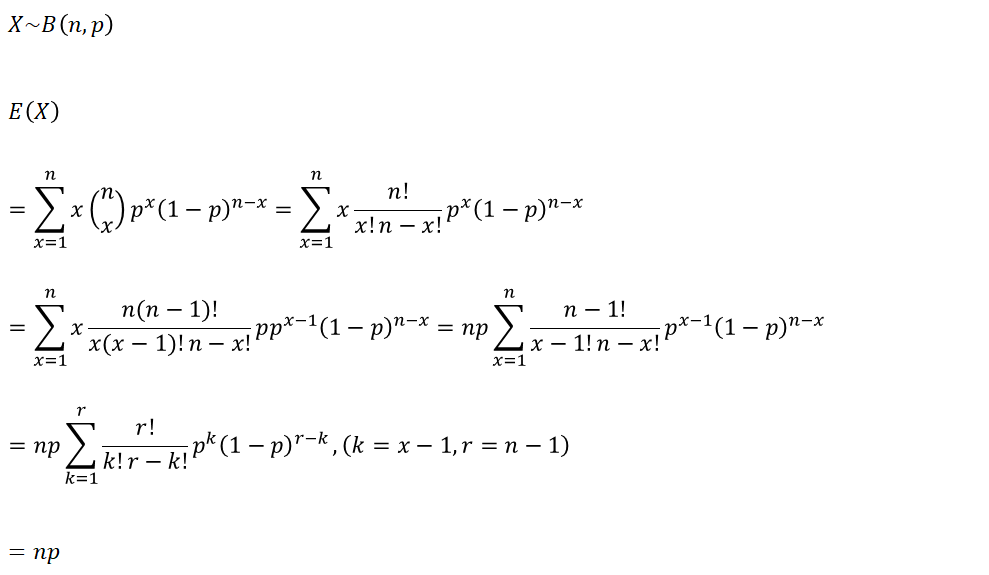
ex) 신입사원의 퇴직 확률이 0.1일 경우, 신입사원 10명의 퇴직 확률
n = 10 (시행횟수 = 신입사원 수)
p = 0.1 (성공확률 = 퇴직 확률)
X (확률변수 = x명이 퇴직할 확률을 구할 때 x)
1-3. 음이항분포
성공의 확률이 p인 베르누이 시행을 독립적으로 반복 시행할 때 k번 성공할 때까지의 시행횟수를 확률변수 X로 하는 경우 성공할 때까지의시행횟수 k, 성공 확률 p를 모수로 갖는 음이항 분포를 따른다.
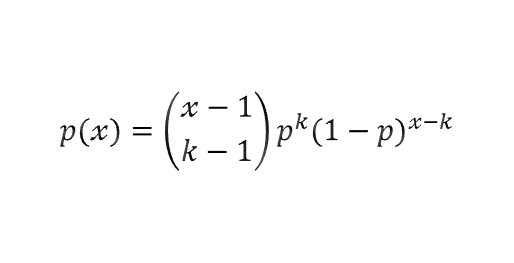

ex) A의 승리 확률이 0.3일 때, 5번 경기를 치루며 2번 성공하려면
n = 5 (시행횟수 = 경기 수)
k = 2 (성공횟수 = A의 승리 수)
p = 0.3 (성공확률 = A의 승리 확률)
X (확률변수 = 2번 이길 때까지 시행횟수)
1-4. 기하분포
성공 확률이 p인 베르누이 시행을 처음으로 성공할 때까지의 시행횟수를 확률변수 X라 하는 경우 확률변수 X는 성공 확률 p를 모수로 갖는 기하분포를 따른다.(음이항분포 k=1)
기하분포는 셀 수 있지만 값이 무한한 무한확률변수이며, 이산확률분포 중 유일하게 무기억성을 갖는다. 무기억성이란 실패를 많이 했다고 해서 실패가 앞으로 성공할 가능성에 영향을 미치지 않는다는 성질이다.
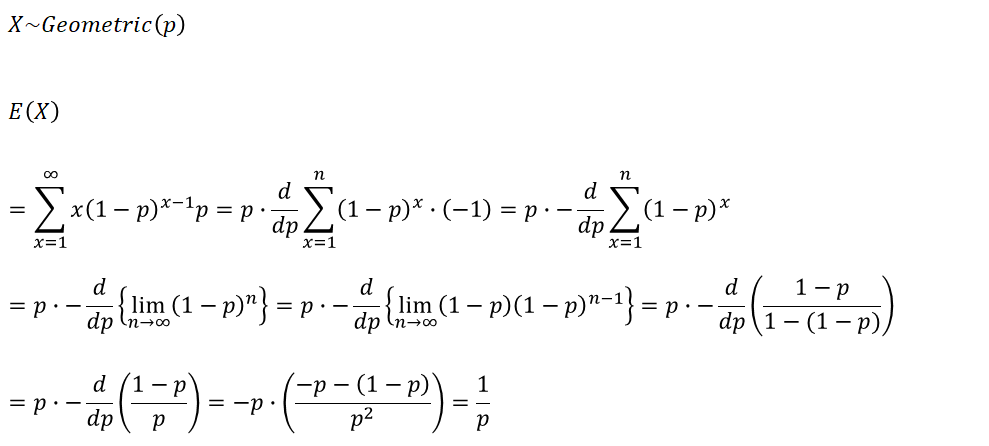

ex) 주사위를 세 번 던져 세 번 째에 처음으로 6이 나올 확률은?
n = 3 (시행횟수 = 주사위 던지는 수)
p = 1/6 (성공확률 = 6이 나올 확률)
X = 3 (확률변수 = x 번 째 시행에 성공)
1-5. 초기하분포
크기 N의 유한모집단 중 크기 n의 확률표본을 뽑을 경우, N개 중 k개는 성공으로, 나머지 N-k개는 실패로 분류하여 비복원으로 뽑을 때 성공 횟수를 X라 하면, 확률변수 X는 N, k, n을 모수로 갖는 초기하분포를 따른다고 한다.
첫 시도 결과에 따라 시도들이 달라지는 종속 관계가 있는 경우 해당 분포를 따른다. 초기하분포는 모집단의 크기 N이 충분이 큰 경우, n개의 시행중 성공확률이 k/N인 이항분포로 근사한다.
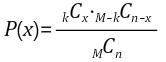
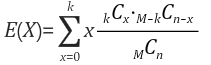
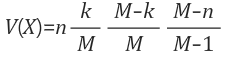
ex) 상자 속에 빨간 공이 90개 파란 공이 10개 있을 때 임의로 1개씩 두 번 꺼내고 다시 넣지 않을 때 1개가 파란 공이 되는 확률은?
N = 100 (모집단 수 = 총 공 개수)
k = 10 (성공요소 수 = 파란색 공 개수)
n = 2 (시행횟수 = 공 선택 횟수)
x = 1 (확인하고자 하는 사건 = 1개 파란공) => 확률변수
P = k/N (모비율)
1-6. 포아송분포
단위시간, 단위면적 또는 단위공간 내에서 발생하는 어떤 사건의 횟수를 확률변수 X라고 할 때 확률변수 X는 λ를 모수로 갖는 포아송 분포를 따른다고 한다. 이 때 λ는 단위시간, 단위면적 또는 단위공간 내에서 발생하는 사건의 평균값을 의미한다.
포아송분포의 X는 셀 수는 있지만 값이 무한한 무한확률변수이다. 또한 단위 시간과 공간에서 발생하는 사건의 횟수는 다르 시간과 공간에 대해서 독립이며, 평균 출현횟수는 일정하다. 포아송분포는 λ >= 5일 때 정규분포에 근사하고, λ < 5일 때 왼쪽으로 치우치고 오른쪽으로 긴 꼬리가 있는 비대칭 분포를 갖는다.
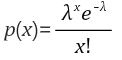

ex) 주말 저녁 시간 당 평균 6명이 응급실 올 경우, 어떤 주말 저녁 30분 내 4명이 도착할 확률은?
x = 4 (구간 내 사건 횟수 = 도착 인원 수) =>확률변수
λ = 3 (구간 내 평균, 확률변수의 구간은 30분 -> 30분 당 평균 3명)
2. 연속형 확률분포
2-1. 균일분포
구간 (a, b)에서 확률변수 X가 균일하게 분포되어 있다면 확률변수 X는 구간 (a, b)에서 균일분포를 따른다고 한다.
2-2. 정규분포와 표준정규분포
정규분포에서 평균 μ는 곡선의 중심위치를 결정하고, 표준편차 σ는 그 곡선의 퍼진 정도를 결정한다. 확률변수 X가 모수 μ, σ를 갖는 정규분포를 따른다고 한다. 정규분포의 왜도는 0, 첨도는 3이다. 정규분포의 양측 꼬리는 x축에 닻지 않고 무한대로 간다.
정규분포는 연속확률분포이므로 확률은 정규곡선 밑의 면적으로 주어진다. 하지만 정규확률밀도함수의 면적을 계산하는 것이 복잡하므로 평균과 표준편차를 이용하여 X를 표준화한 후 구한다.
정규분포는 이항분포의 근사, 중심극한정리 등으로 통계학에서 매우 유용하게 쓰이는 분포 중 하나이다. 이 때 중심극한정리의 의미는, "모집단에서 표본크기가 n인 표본을 반복해서 추출했을 때 각 표본 평균들이 이루는 분포는 표본의 크기가 커질 수록 모집단의 평균이 μ, 표준편차가 σ/root(n)인 정규분포에 가까워진다."이다.
https://bookdown.org/mathemedicine/Stat_book/normal-distribution.html
기초통계 개념정리
This is a basic statistics book written by JSKIM.
bookdown.org
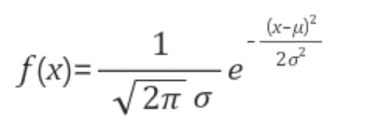
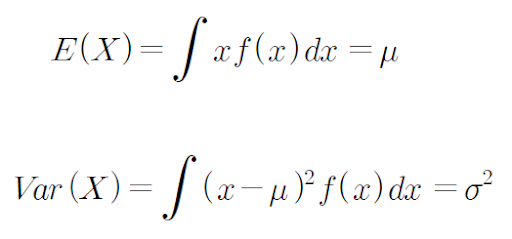
특정 평균과 표준편차를 갖는 정규확률밀도함수의 면적을 계산하는 것은 복잡하므로 평균과 표준편차를 이용하여 확률변수를 표준화한 후 구한다. 표준화란, 확률변수 X에 대해 Z = (X-μ,)/σ로 변환시키는 것이고, 이 때 표준화 확률변수 Z는 평균이 0, 표준편차가 1인 표준정규분포를 따른다.
2-3. 지수분포
포아송 분포가 단위시간 내에서 발생하는 사건의 횟수(이산형!!)의 분포인 반면 지수분포는 한 번의 사건이 발생할 때까지 소요되는 시간(연속형!!)의 분포이다. 지수분포는 어떤 사건이 포아송 분포에 의해 발생될 때 지정된 시점으로부터 이 사건이 일어날 때까지 걸린 시간을 측정하는 확률분포로 확률변수 X는 한 번의 사건이 발생할 때까지 소요되는 시간이고 λ는 단위시간 동안 평균적으로 발생한 사건의 횟수이다.
지수분포는 연속확률분포 중 유일하게 무기억성의 성질을 갖는다.

ex) 사람들이 지하철 개찰구 통과하는 사이 간격이 평균 3분인 지수분포를 따르는 경우, 연속한 두 사람이 통과하는 시간이 2분 이내일 경우는?
λ = 1/3 (단위시간 동안 평균 발생 횟수 = 평균 1분 간 1/3번)
x = 2 (사건이 일어날 때까지 걸린 시간, 확률변수)
2-4. 감마분포
포아송 분포와 지수분포를 확장한 감마분포는
α번의 사건이 발생할 때까지의 대기시간 분포이다. 즉 지수분포의 일반화된 형태로, 확률변수 X가 모수 α, β를 갖는다. 여기서 β는 λ/1로, 한 번의 사건이 발생하는 시간, 즉 두 사건 사이의 평균적인 간격이다.
ex) 물고기를 30분에 한 마리씩 잡는 어부가 4마리의 물고기를 잡을 때 걸리는 시간이 1시간에서 3시간 사이일 확률?
α = 4 (사건 발생 횟수 = 4마리 잡을 때까지)
λ = 2 (단위시간 또는 단위공간 당 사건 발생 횟수 = 1시간에 평균 2마리 잡음)
β = 1/λ = 0.5 (평균적으로 1회의 사건이 발생하는 시간? = 한마리 평균 30분)
x = (1, 3) => 분포에서 x가 1~3인 범위 면적이 해당 확률임
2-5. 카이제곱분포
카이제곱분포는 감마분포의 특수한 경우로서 α=n/2, β=2인 경우를 자유도 n인 카이제곱분포라고한다. 카이제곱분포는 모집단이 정규분포인 대표본에서 모분산을 추정/검정하거나, 비모수 검정 중에서 범주형 변수들에 대한 적합도 검정, 독립성 검정, 동질성 검정을 하는데 사용한다.
카이제곱분포의 경우 일반적으로 직접 어떠한 확률을 구할 때 사용하는 분포가 아니라, 신뢰구간과 가설검정 등의 여러 분석에서 사용하는 분포이다.
https://math100.tistory.com/44
카이제곱분포란?
통계에서 보통 무엇인가를 조사하고 분석할 때, 데이터의 중심위치를 파악하는 것이 중요한데, 이 중심위치를 나타내는 대표적인 척도가 평균이다. 그리고 평균을 기준으로 각 데이터가 흩어져
math100.tistory.com
https://diseny.tistory.com/entry/%EC%B9%B4%EC%9D%B4%EC%A0%9C%EA%B3%B1-%EB%B6%84%ED%8F%AC
카이제곱 분포 이해하기
관련글 확률, 확률변수 그리고 확률분포 1. 들어가며 통계학은 기술통계와 추론통계로 구분되는데, 기술통계와 추론통계를 연결해주는 것이 확률분포이다. 그런데 확률분포를 이해하기 위해서
diseny.tistory.com
2-6. t분포
표본 평균을 표본 분산으로 표준화한 값이 따르는 확률분포를 t분포라고 한다. 주로 모분산을 모르는 상황에서 표본 평균을 추정/검정할 때 사용한다. t분포는 자유도가 증가할 수록 표준정규분포에 수렴하며, 주로 30개 이하의 소표본에 사용한다. 카이제곱분포와 마찬가지로 직접 어떠한 확률을 구할 때 사용하는 분포가 아니라, 신뢰구간과 가설검정 등의 여러 분석에서 사용하는 분포이다.
2-7. F분포
F분포는 두 모집단의 모분산 비의 추정/검정과 세 집단 이상의 모평균 비교에 주로 사용한다. 카이제곱분포와 마찬가지로 직접 어떠한 확률을 구할 때 사용하는 분포가 아니라, 신뢰구간과 가설검정 등의 여러 분석에서 사용하는 분포이다.
'Statistics' 카테고리의 다른 글
| 추정과 가설 검정 간단 정리 (0) | 2024.01.15 |
|---|---|
| F-분포(F-distribution) (1) | 2024.01.12 |
| t-분포(t-distribution, Student's t-distribution) (1) | 2024.01.12 |
| 카이제곱분포(Chi-Square distribution) (0) | 2024.01.12 |
| 정규분포(Normal distribution) (0) | 2024.01.12 |



