반응형
통계적 추론의 목적
통계적 추론의 목적은 표본의 정보로부터 모집단에 대한 정보를 얻는 것이다. 여기서 모집단의 특성을 나타내는 상수들을 모수라 하고, 표본의 특성을 나타내는 상수들을 통계량이라고 한다. 예를 들어 모집단의 모수인 평균, 비율, 분산을 추정하거나 가설 검정을 할 때, 통계량인 표본으로부터 얻은 표본평균, 표본비율, 표본분산을 사용한다. 각 통계량들은 특정 확률분포를 따르기 때문에 이 분포들을 활용한다.
추정의 종류
추정은 점추정과 구간추정으로 나뉘며, 점추정은 단순히 표본평균, 표본분산, 표본비율을 계산하는 방법이다. 이 때 추정값들이 얼마나 정확히 모수를 추정하는지 알 수 없기 때문에 오차의 개념을 추가하여 구간으로 모수를 추정하는 방법이 구간추정이다.
가설 검정
가설 검정은 표본에서 얻은 사실(통계량)을 근거로 하여 모집단에 대한 가설이 맞는지 통계적으로 검정하는 분석방법이다.
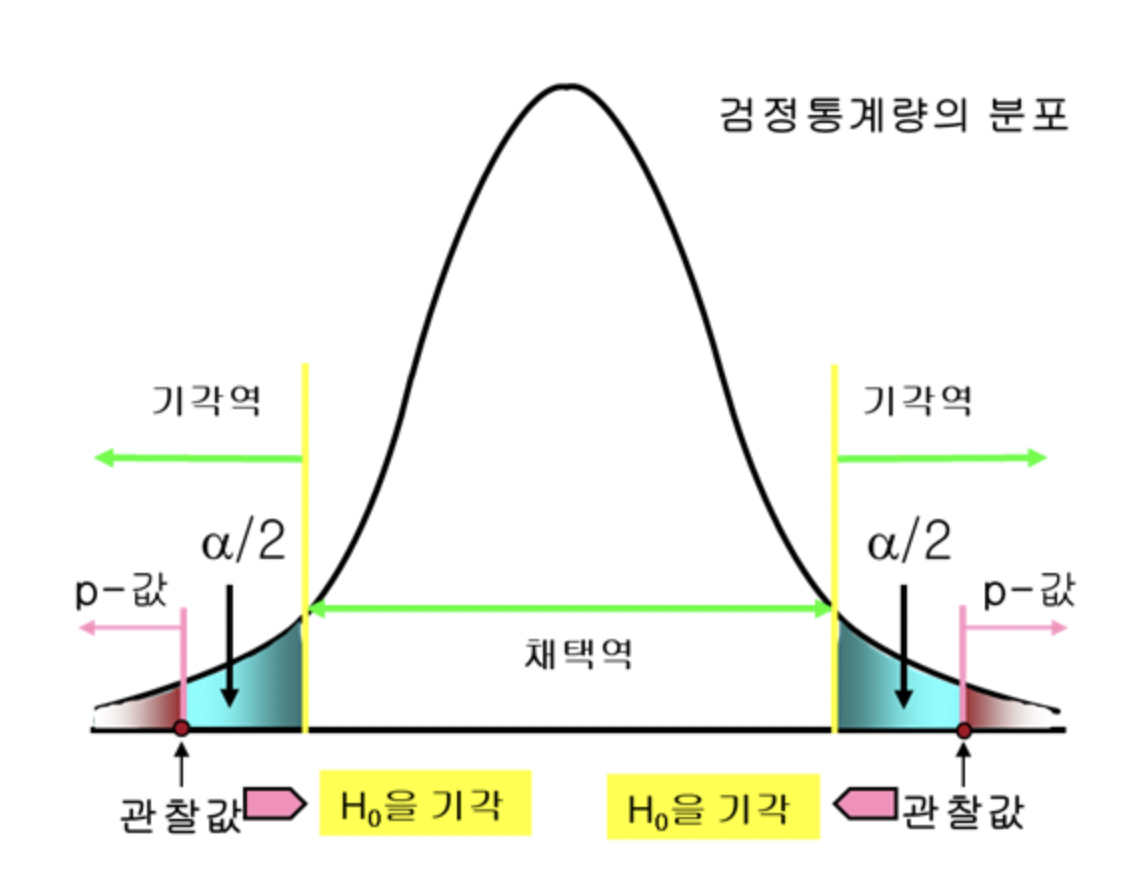
1. 가설 설정
- 귀무가설 - 직접 검정 대상이 되는 가설로, 표본을 통해 '이 자료들은 이러할 것이다'라고 세운 가설이다. 귀무가설은 증명된 바 없는 주장이나 가설로, 이 귀무가설이 옳다는 가정하에 검정을 시작한다. 검정의 목표는 귀무가설을 기각하는 것이다.
- 대립가설 - 귀무가설에 대립되는 가설로, 새로운 주장 또는 실제로 입증하려는 가설이다. 대립가설은 채택이 목표이다.
2. 유의수준 설정
- 임계값 - 주어진 유의수준에서 귀무가설의 채택과 기각에 관련된 의사를 결정할 때 그 기준이 되는 값이다. 여기서 유의수준이란, 귀무가설이 옳음에도 기각할 확률로, 일반적으로 주어지는 값이다(보통 0.05 또는 0.01). 여기서 주어진 유의수준을 통해 기각영역과 채택영역을 분리시킬 때, 그 경계가 되는 값이 임계값이다.
3. 표본 수집 및 검정통계량 계산
- 검정통계량 - 수집한 데이터로 계산한 '확률변수'이다. 여기서 확률 변수란 특정 사건(추출한 표본의 통계량)을 어떠한 수치값으로 변환한 것인데, 이 값은 이 값이 발생할 확률값과 대응시킬 수 있다. 정규분포의 Z 값을 예시로 들면, 표본에서 구한 통계량(표본 수, 표본평균, 표본표준편차)을 이용하면 Z을 구할 수 있고, 계산한 Z 값을 표준정규분포에 대입하면 확률을 계산할 수 있다.
- p-value - 검정통계량을 확률분포에 대입시켰을 때, 해당 검정통계량이 나올 확률을 의미한다.
4. p-value와 유의수준을 비교해 귀무가설을 기각하거나 채택한다.
만약 p-value가 유의수준보다 클 경우, 귀무가설의 분포내에서 표본을 추출하다 보면 우연히 발생하는 차이라고 볼 수 있다. 따라서 이 경우 귀무가설을 기각할 수 없고, 반대의 경우 기각하며 대립가설을 채택한다.
5. 오류
- 1종 오류 - 1종 오류란 귀무가설이 참인데 기각한 경우를 말한다. 즉 귀무가설을 기각하고 대립가설을 채택했지만 이것이 잘못된 검정이었음을 뜻한다. 이에 따르면 p-value는 1종 오류를 얼마나 범할 것인가의 확률을 나타내기도 한다. 즉 p-value가 5%라면 100번 검정했을 때 5번 정도 1종 오류가 발생하는 것이다. 또 이에 따라 유의수준은 1종 오류의 상한선이라고 말할 수 있다. 따라서 검정결과 p-value가 유의수준보다 낮다면 상한선을 벗어나지 않으므로 귀무가설을 기각한다.
- 2종 오류 - 2종 오류란 귀무가설이 거짓인데 참으로 판단한 경우를 의미한다.
- 1종 오류와 2종 오류는 trade-off관계이다. 1종 오류를 고정한 채로 2종 오류를 줄이려면 표본의 크기를 크게 하는 방법이 있다.

반응형
'Statistics' 카테고리의 다른 글
| 이표본 검정(Two-sample)(feat.Python) (1) | 2024.01.17 |
|---|---|
| 일표본(One-sample) 검정(feat.Python) (0) | 2024.01.16 |
| F-분포(F-distribution) (1) | 2024.01.12 |
| t-분포(t-distribution, Student's t-distribution) (1) | 2024.01.12 |
| 카이제곱분포(Chi-Square distribution) (0) | 2024.01.12 |



